
背景:之前弄了个GPT的网站,也算是为爱发电了好几个月,Claude3 发布之后,我也是第一时间接入了。一开始用的是最强大的 Claude3-Opus 模型,不过可能是因为用的是第三方API,稳定性相比之前自购的 OpenAI 的 GPT API 稍逊一筹,导致我得经常把 Opus 换成 Haiku 来缓解回复超时的问题。就是因为这个契机,我开始了和浏览器缓存机制的较量。
成品:LLM - wljay Network Service
因为我这个 GPT 网站的网页 Html 是完全的前端,几乎所有逻辑也都是(API 密钥相关的鉴权逻辑不是)基于 Javascript 在前端执行的,这就导致我每次在服务器端调整网站后,如果用户的浏览器缓存了网站的相关内容,他们也无法看到网站的最新版本。更加致命的是,有时我因为稳定性不良调整了模型相关逻辑,这些用户的访问网站时由于浏览器缓存,依然无法同步我应用修复措施之后的模型。我经常收到来自这部分用户的反馈,所以我就有了在前端控制浏览器缓存的想法。

一开始的时候,我直接想到利用 localStorage 来存储版本号,然后用 PHP 写一个能返回当前版本的接口,再基于 Javascript 写一个 fetch 来判断 localStorage 中的版本号和服务器端是否一致的条件逻辑。如果版本不一致,使用 location.reload(true)来使浏览器强制刷新网页。当时的代码,这是纯纯的踩坑了,当教训,不要参考:
// PHP 接口返回的版本号示例
{
"version": "2.0.240404.0408"
}// index.html 与 GPT 逻辑 JS 中的创建 localStorage 对象逻辑
<script>
const siteVersion = '%版本号%';
localStorage.setItem('WebVersion', siteVersion);
</script>// 加载 JS 判断当前 localStorage 版本与服务器版本是否一致,不一致则刷新
async function getServerVersion() {
try {
const response = await fetch("%版本号返回接口%");
const data = await response.json();
return data.version;
} catch (error) {
console.error("获取版本号失败:", error);
return null;
}
}
async function checkVersion() {
const serverWebVersion = await getServerVersion();
const localVersion = localStorage.getItem("WebVersion"); // 从 localStorage 获取版本号
if (serverWebVersion && serverWebVersion !== localVersion) {
if (confirm("网站有新版本,请刷新页面以获取最新内容。")) {
location.reload(true); // 刷新页面(反面教材!true 参数强制刷新只有 FireFox 支持,其他所有浏览器都不支持!)
}
}
}
checkVersion();
// 每隔一段时间检测一次
setInterval(checkVersion, 60000); // 每60s检测一次这些代码一开始测试的时候自我感觉良好,可是到后面实测发现好像并没有什么卵用,因为 location.reload(true) 只有 FireFox 支持触发忽略缓存强制刷新,其他的浏览器不支持 true 参数,所以只能识别 location.reload(),也就是所谓的常规刷新。
也就是说,当我更新 index.html 和 JS 文件之后,用户端检测到版本不一致后进行的刷新只有刷新 index.html 的作用。JS 往 localStorage 写入的版本依然是旧版本,又由于 setInterval(checkVersion, 60000) 设置的60s间隔检测,这就会导致“循环刷新”,当用户遇到这个问题时根本无法使用网站。

很不幸的是,当时我发现这个问题的时候,我已经把网站的 Changelog 都写出来了,这下真的汗流浃背了。我紧急下线了这个功能,同时开始重新规划如何解决浏览器缓存的问题。
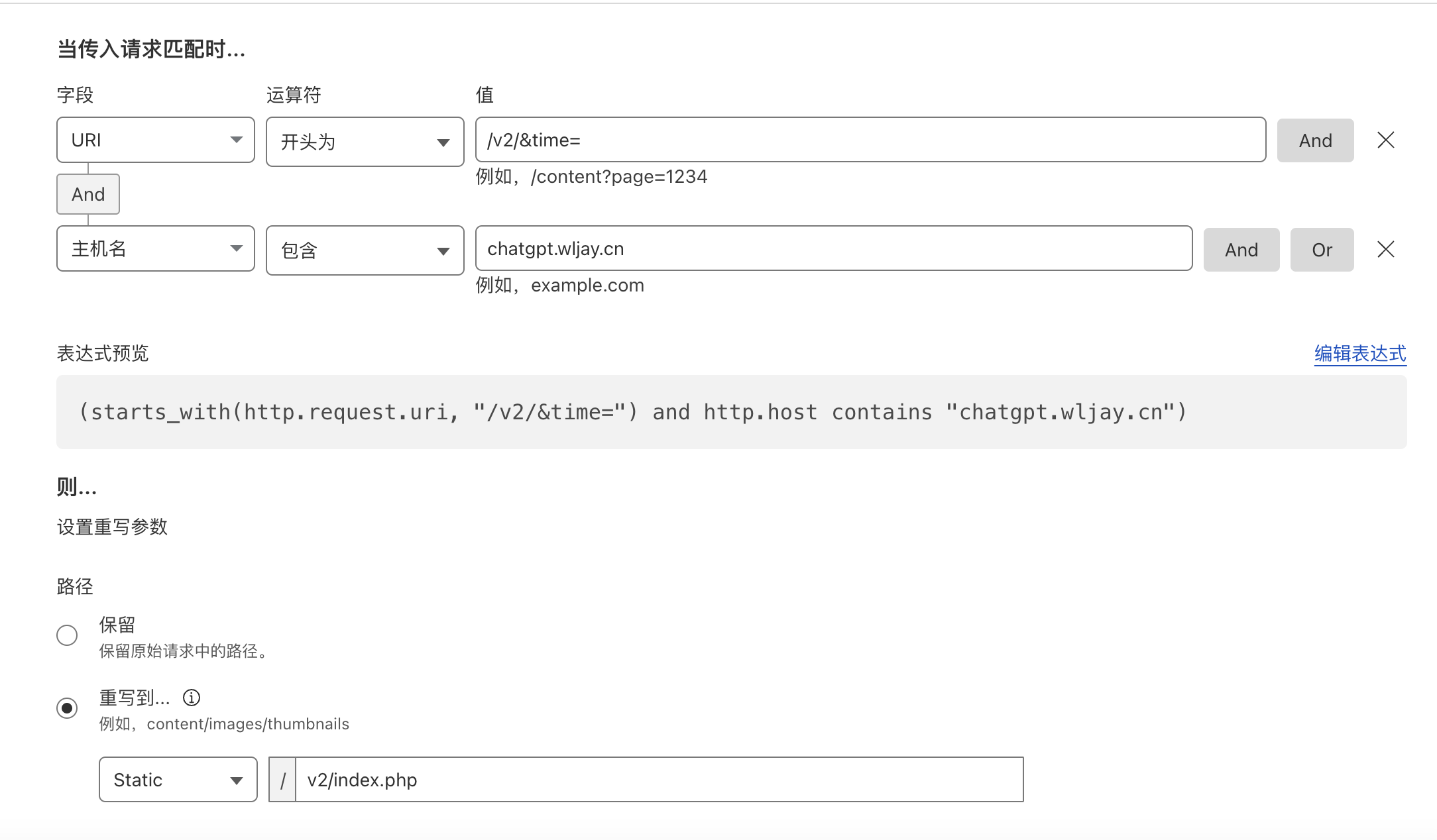
这次我想到了时间戳,一开始我准备在 URL 后基于系统时间加上“查询参数”,这种方法的优点是方便,只需捕获 URL 的值,然后使用 getTime() 方法加入 UNIX 时间戳即可。但是这样会明显加大源站负载,同时会影响网站的缓存。所以我灵机一动,想到了 Cloudflare 的转换规则,将源 URL 转换为目标 URL ,它发生在 Web 服务器完全处理请求之前,在 Cloudflare 全球网络上执行重写,而无需访问源站。重写对网站访问者不可见,因为浏览器中显示的 URL 不会更改。这样就很好地避免了源站压力过大的问题,同时也不影响缓存的目标。
于是,我修改了判断版本号不一致时的 JS 逻辑:
async function checkVersion() {
const serverWebVersion = await getServerVersion();
const localVersion = localStorage.getItem("WebVersion"); // 从本地存储获取版本号
if (serverWebVersion && serverWebVersion !== localVersion) {
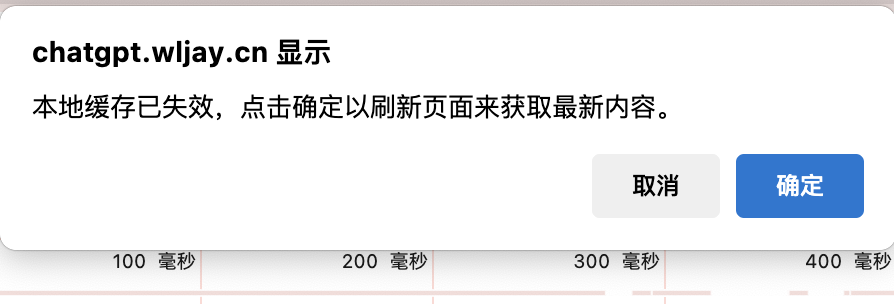
if (confirm("本地缓存已失效,点击确定以刷新页面来获取最新内容。")) {
let url = location.href;
const timeIndex = url.indexOf("&time="); // 判断 URL 内容中是否已含有时间戳
if (timeIndex !== -1) {
url = url.substring(0, timeIndex); //有即删除原有的时间戳
}
window.location.href = url + "&time=" + ((new Date()).getTime()); // 添加新的时间戳后刷新页面
}
}
}代码会获取当前页面的 URL,并检查 URL 中是否已经包含时间戳参数 &time=. 如果已经包含,它会删除原有的时间戳。然后,它会在 URL 后添加一个新的时间戳参数 &time=,并刷新页面。同时,我也按照此逻辑在 Cloudflare 编写了一个 URL 重写规则,其旨在保证参数被服务器正确读取。
然后就是 GPT 逻辑 JS 的更新,对于这种小文件,在后面添加查询参数也无妨,所以我利用 Javascript 编写了一个简单的逻辑,捕获当前 URL,如 URL 中含有为了更新缓存而添加的时间戳参数,即在请求时在 JS 的 URI 后添加基于 UNIX 时间戳的查询参数。
<script>
var url = window.location.href; // 捕获 URL
if (url.indexOf('&time=') > -1) { // 判断 URL 中是否含有时间戳参数
var script = document.createElement('script');
script.src = '%JS 文件%?time=' + new Date().getTime();// 如果有即添加相应的时间戳
document.head.appendChild(script);
} else {
var script = document.createElement('script');
script.src = '%JS 文件%'; // 如果不含有时间戳参数,即按照正常流程加载
document.head.appendChild(script);
}
</script>在更新网站时,我必须权衡服务器性能和缓存效率。如果在每次请求中都添加时间戳,虽然可以确保内容是最新的,但这会导致服务器压力过大,因为 Cloudflare 缓存的优势将不复存在。这样做的后果是,每次用户访问都会向服务器发送请求,而不是使用缓存,这与我们使用 URL 重写规则来减轻服务器负载的初衷相违背。因此,我选择了一种折中的方法:只在必要时通过时间戳强制更新缓存。这样,我就可以避免在 index.html 中写入 localStorage 逻辑,而是将这一逻辑集中在核心的 Javascript 文件中。这种做法不仅减少了服务器的负担,而且通过有效利用时间戳,解决了由浏览器缓存导致的版本滞后问题。
到现在为止,浏览器的过度缓存就已经被成功规避了。当用户浏览器的本地缓存与服务器端的版本不同时,网页会弹窗提示刷新缓存,这时网页的请求就会被附加 UNIX 时间戳,而浏览器也会因此放弃原有的缓存,重新下载最新版本的 JS 文件。
发表回复