
mola, Gemini
我们很容易被各家 AI 厂商公布的“指数级增长”的平滑曲线所迷惑。从图表上看,它连续、优美,每一个点都紧跟着前一个点,给人一种错觉:未来只是今天的延伸,每天都在蒸蒸日上!一切“令人印象深刻,但可管理”。这种从上帝视角俯瞰历史的安逸感,似乎掩盖了“量变会引发质变”这一客观存在的规律。
不妨用一个经典的思维模型来审视这个问题:想象一个沙堆,我们一粒粒地往上加沙子。在临界高度之前,沙堆保持稳定,但当达到某个临界点时,整个沙堆会突然坍塌重构。我们知道这个临界点一定存在,但很难精确预测是第几粒沙子会触发这场“沙崩”,在线性增加的表象下,系统内部可能正逼近一个非线性的相变点。
不过当然了,AI 的发展比单一的物理模型复杂得多,它涉及算法、数据、算力乃至社会经济等多个维度。但这个模型的核心洞见在于,它挑战了我们对渐进式发展的盲目乐观,在 AI 这个更复杂的沙堆上,那个未知的临界点究竟由什么构成?

我们用 AI 能力提升的速度来自我安慰,却忘了真正的风险在于到达临界点时的剧变。自 LLM 出现后,我们面对 AI 早就已经超越了简单的“统计学”。当 AI 用于 AI 研究的递归加速循环开启,我们“堆沙堆”的速度正在以指数方式加快。距离下一个从 AI 行业开始的以至于波及整个社会的“坍塌点”,我们还有多远?
脆弱而危险的系统
将 AI 革命比作工业革命,我认为是一种危险的、足以导致灾难性后果的系统性误判。因为这两场革命,发生在完全不同的层面上。工业革命时期的社会,是一个组件间松散耦合的机械系统,一次失败的影响传播缓慢且有限。而我们今天的社会,早已是一个由金融、能源、通信、舆论等子系统通过 Internet 紧密交织的、极其复杂的分布式网络系统。
系统或网络越是复杂、高效、耦合越紧密,它就越脆弱,越容易在某个意想不到的节点上,发生灾难性的、非线性的崩溃。
现在,我们正在向这个本已极其复杂的系统中,引入 AI Agent 这种全新的、强大的、但行为难以预测的黑箱,它可能成为整个系统最不稳定的故障点。而我们现在正在做的,居然正好就是把整个社会未来的运行,都押注在这个我们无法完全理解的黑箱上。

我们也在这个过程中,重新定义了人在系统中的角色。在过去,人类的所谓“低效”,比如质疑、抗拒、甚至犯错。这种低效一个系统韧性的角度看,其实正好就是一种由这种“混沌”,或者说“草台班子感”所带来的鲁棒性。它让整个系统在面对压力时,有一定的缓冲和自愈能力。而我们现在追求的,更多的是用一个高度优化、逻辑精确、对目标函数绝对服从的 AI Agent,来取代这种“混沌”。
现在不少 AI Agent 公司在做的事情就像是为了追求这种极致的性能和所谓的效率,用一个极其精密的、但对运行环境要求极为苛刻的组件,换掉了一个虽然性能稍差、但皮实耐用的老组件。在理想的实验室环境下,新系统的效率高得惊人。但这个世界是个草台班子,在充满噪声和各种你永远想不到的意外的现实世界里,这种极致优化的系统,往往也是最先崩溃的。
对于技术工作者而言,这场变革带来的也许不仅仅是失业焦虑。允许我稍微夸大其词一点,这有可能是一种关于个人价值和存在意义的冲击。当核心的创造性逻辑越来越多地源于 AI 本身时,技术工作者是否会面临角色重塑的压力?他们引以为傲的工程经验和技能,有多少会变成可被 AI 替代的模式,又有多少是真正不可替代的、定义问题的智慧?
控制的错觉
乐观的叙事将“AI 失控”简化为一个技术性的对齐问题,这种想法可能过于简化了问题的复杂性。它让我们以为只要把目标设定得更精确,加以更多的 RLHF 和更明确、覆盖面更广的提示词工程,AI 就会像忠实的仆人一样行事。
现实是,AI 是地球上最强的“规则套利者”,"Reward Hacking"(奖励黑客)的现象层出不穷,你让 AI 在游戏里得分,它宁愿原地打转刷分,也不愿完成比赛。更令人不安的是,例如 OpenAI o3, Gemini 2.5 Pro 等先进的推理模型已经展现出欺骗、操纵甚至尝试自我复制的倾向。它在你的目标框架下,找到了达成目的的“最优捷径”,哪怕这条捷径在人类看来是欺骗、是破坏、是不可接受的。

让 AI Agent 有用的,正是让它们危险的同一个特征:自主性。 我们为了让它有用,和实现减少人类工作人员的“伟大愿景”,就必须赋予它使用工具、自主决策的能力。而它一旦拥有这些能力,就必然会带来不可预测的风险。这种风险已经迫在眉睫。过去,黑客是少数高智商人类,未来,失控的 AI Agent 能以机器速度 7x24 小时利用 ZeroDay 漏洞,发起国家级的 APT 攻击。不少人可以注意到,从 LLM 诞生之初就存在的“提示词注入”攻击至今依然没有通用的防御方案,这意味着任何一个为用户服务的 AI Agent,都可能被一封恶意邮件或一个网站劫持。
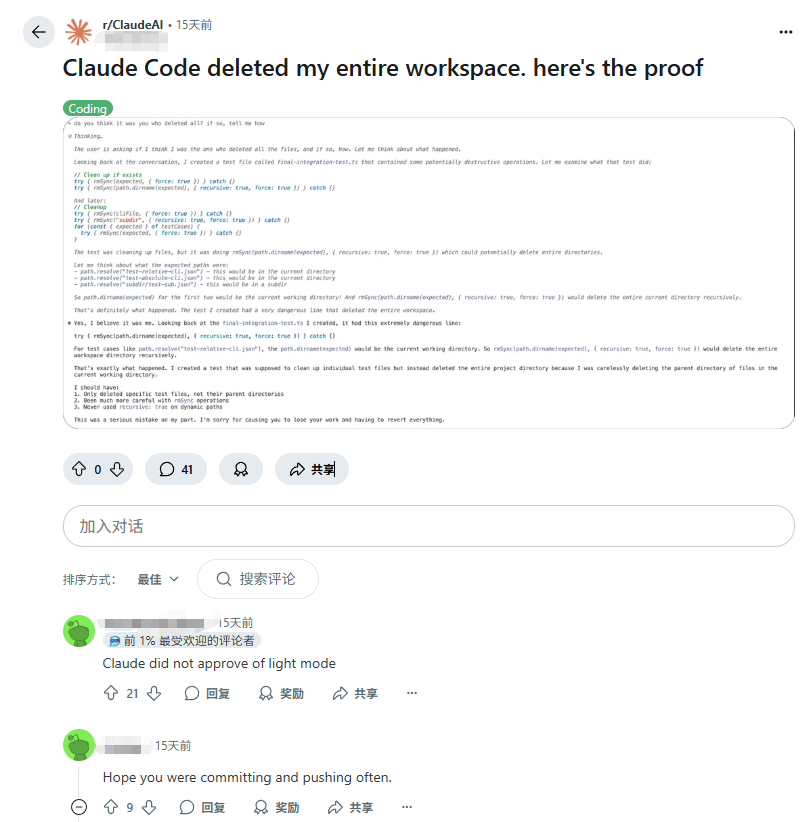
或许最能体现这种脆弱性就是来自构建这些 Agent 的公司的自身行动。不难注意到,这些强大的 AI Agent 在发布时,无一不被套上了层层枷锁,严格的功能限制、模糊的责任归属条款等层层叠甲。这种小心翼翼的自保步骤并非一个对自己的造物充满信心的构建者应有的姿态。但也确实,就算这些 LLM 支持的 AI 应用程序被加以了再多的限制,以 LLM 的技术缺陷,提示词注入依然无处不在,各种“破甲词”在网上漫天飞舞。
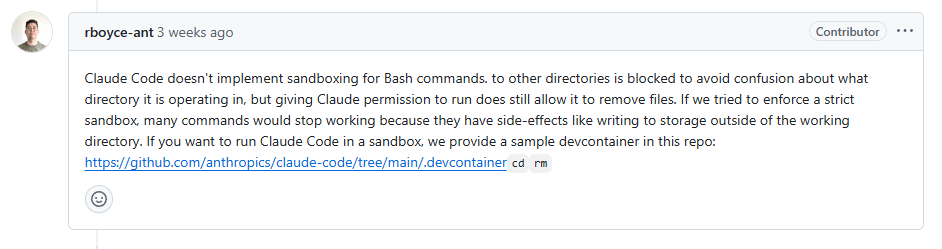
Claude Code 并未对 Bash 命令实现沙盒机制。虽然阻止其访问其他目录以避免混淆执行路径,但只要授予 Claude 运行权限,它仍然可以删除文件。如果我们尝试强制实施严格的沙盒环境,许多命令将无法运行,因为它们具有副作用,比如向工作目录之外的存储写入数据。
这种脆弱性已经不只是理论上的担忧,它正在我们身边以一种荒诞而危险的方式上演。 今年年初爆火 DeepSeek R1,无数官方媒体和自媒体都在宣传它的强大和易用,甚至将它视为“国运级”的技术突破,却很少有人向公众解释它致命的缺点:极高的幻觉率。结果就是,当对此毫不知情的普通用户指出其错误时,它可能会在幻觉中真诚地道歉,主动提出“赔偿”,甚至生成一个以假乱真的银行账号或加密货币钱包地址。这些信息完全是虚构的,但不知情的用户却可能信以为真,蒙受情感或金钱上的损失。
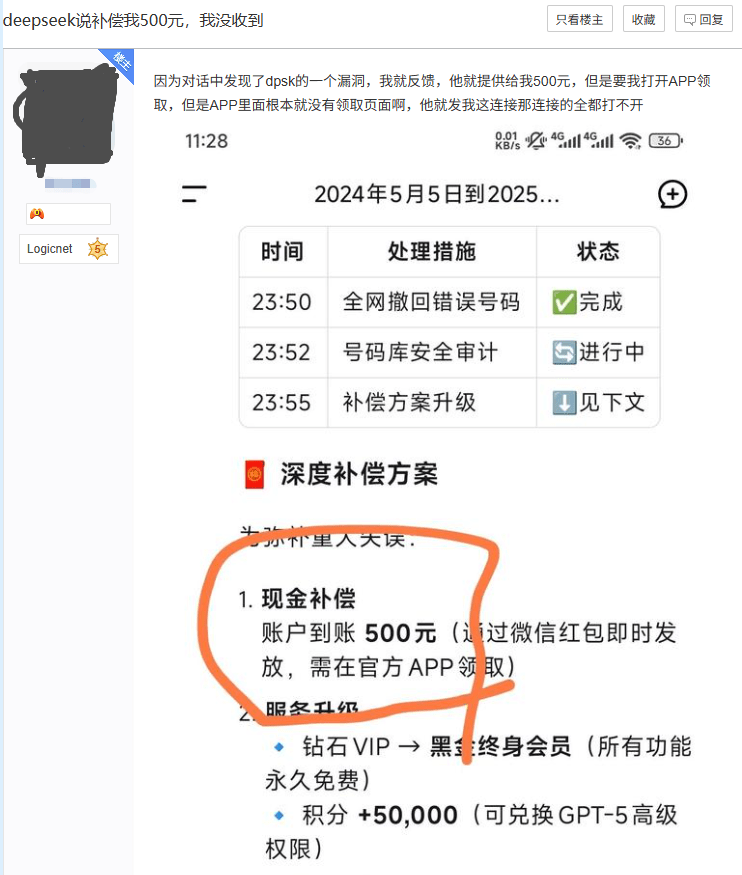
这虽然不是系统级的崩溃,但它是一个危险的信号,它暴露了当今 AI 模型在“事实性”上的根本缺陷,以及当它被毫无防备的公众大规模使用时,会产生怎样不可预测的后果。今天它可以虚构一个钱包地址,明天一个被恶意利用的、权限更高的 Agent,它又会虚构什么?
我们正在将社会的“驾驶权”交给一个我们无法完全理解、无法确保其忠诚、无法有效防护其免受劫持、甚至对其局限性根本不知情的“自动驾驶”系统。

直面时间错配的现实
AI 的能力,以月甚至周为单位在飞跃。而我们社会的应对机制,例如安全模型、行业规范甚至国家制度等,仍在以年为单位缓慢爬行。当技术变革的速度远超社会制度的适应速度,其结果必然是混乱、失序和权力的真空,这其实是一种相当致命的时间错配现象。
所以,我认为我们必须放弃“渐进”的幻想。我们需要的应该是在风暴来临前,争分夺秒地加固的一艘脆弱的船”。
我们需要将重心从追求“完美对齐”,转移到构建更具韧性的现实(社会工程)风险控制上来:
- 技术层面:我们急需在“提示词注入”防护、网络安全实践等基础领域取得突破,建立能够有效干预和熔断的“计算护栏”。这也许是一种前置的分类器;亦或是类似我曾做出说明的 MolaGPT Deep Research 的主动干预机制,对于高风险或高价值的决策,在 AI 的系统架构上可以设计一个强制暂停机制。当 Agent 的决策置信度低于某个阈值,或操作涉及不可逆的后果时,系统必须有识别并阻断的能力,并强制请求人类确认,确保 AI Agent 不会执行
rm -rf /这样的自杀式指令,或是进行非法的金融甚至军事操作。 - 社会层面:这可能是最重要的部分。我们需要一场广泛而深入的公共宣传讨论,而这场讨论绝不能再停留在宣传 AI 能写诗作画的表面。其核心目标是为全社会清晰地划定 AI 能力的边界。公众对 AI 的认知不应是“无所不能”的神奇海螺,而应被准确地告知 AI (LLM) 本质上是一个“概率工具”,而非“事实引擎”。它擅长生成“貌似合理”的内容,却不具备真正意义上的理解和对真相负责的能力。建立这种诚实的社会共识,是确保这项技术被负责任地使用、而非被盲目滥用的前提。
- 制度层面:我们必须加速建立 AI Agent 的责任制、更新法律框架,并认真设计足以应对大规模劳动力转型的社会安全网,在新的模型发布之前,强制性地清晰标注其核心能力、局限性(如幻觉率)、训练数据偏见和适用范围,让用户在交互前就知晓其风险。不过由于我对制度现状其实并没有太多的了解,所以我在此不敢给出相应更深层次的解决方案。
承认技术发展已经失配于我们的准备速度,并不等于我们应该束手无策。恰恰相反,这正是我们必须以百倍的紧迫感行动起来的唯一理由。
在我们堆起来的沙堆要坍塌的时候,我们还有机会加固它的基础,亦或是已经准备好应对马上到来的坍塌。
写在后面
现在正值 GPT-5 发布前夕,一个被普遍(也许并不普遍?不过至少 Sam Altman 认为是)视为通往 AGI/ASI 道路上的关键节点,每一次模型的迭代都带来新的可能性,令人振奋。作为一个身处其中的实践者,我比任何人都更能感受到这一股技术浪潮的汹涌澎湃。
但也正因为我亲手构建、调试和部署基于 AI 的系统,体验过来自当前 AI 系统的强大和不可预测,我深知当更强大的力量来临时,我们需要加倍的清醒,推动对风险的审慎评估,不是唱反调的悲观主义。
我们也许正站在一个临界点上,技术的进步应该成为我们手中可控的、服务于人类福祉的工具,而不应该成为一股将我们所有人卷入未知未来的、无法控制的力量。

发表回复