
暨 MolaGPT 开发日记 - 其(六)
本文详述了 MolaGPT 前端的一次局部性能重构。旨在解决因用户侧状态数据规模膨胀(数千条对话历史)而导致的严重性能瓶颈,包括 UI 线程长时间阻塞和部分移动端(iOS、macOS 这类限制较为严格)浏览器内存溢出崩溃的问题。
问题的出现与定位
在最近的一次迭代中,我为 MolaGPT 的 UI 引入了 backdrop-filter 属性,以实现细腻的毛玻璃质感。然而,更新上线后,我注意到标签页崩溃的现象。因为是刚刚上线前端特性,所以我的初步分析就自然将矛头指向了新增的视觉特效,但我在之后对页面进行调试时发现了一个更深层次的问题:所有崩溃案例均发生在拥有海量对话历史(数百甚至数千条)的用户身上。
所以,问题真正的根源不在 MolaGPT 的前端新特性,这一系列前端更改也许只是压死骆驼的最后一根稻草,其根源应该是状态管理和渲染机制。我来详细梳理一下整个过程:
当 MolaGPT 加载时,init 逻辑会同步从本地的 IndexedDB 读取全部对话元数据,并试图一次性将其渲染到侧边栏的 DOM 中,该这个过程的计算复杂度应该是与对话数量呈正比例关系。当对话只有几十条时,一切安好。但当这个数字变成几百上千时,灾难就发生了。浏览器需要在一瞬间操作巨量又复杂的 DOM,导致主线程被完全锁死,整个页面进入冻结状态,随后就是内存快速耗尽撞墙,最终导致浏览器抛出页面崩溃的错误。

我承认这是一个建立在屎山代码上的架构错误。我一开始低估了用户与产品之间长期陪伴会积累下的数据量。
应急响应,上线 HotFix
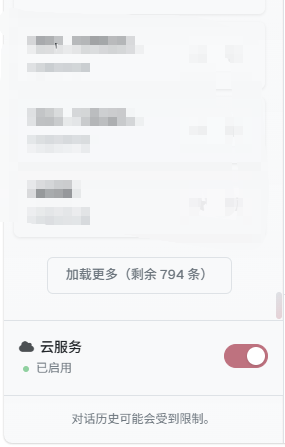
为了立刻解决崩溃问题,我直接采取了最直接有效的方案:列表虚拟化,说得通俗一点,就是分块加载。
逻辑很简单:不再一次性显示所有对话,而是先加载最上面的 50 条。当用户滚动到底部,或者点击一个“加载更多”的按钮时,再加载下面的 50 条。
// 伪代码:分块加载的核心逻辑
function renderConversationListInBatches(allConversations) {
const BATCH_SIZE = 50
let renderedCount = 0;
const renderNextBatch = () => {
// 从总列表中切出当前需要渲染的一小批
const batchToRender = allConversations.slice(renderedCount, renderedCount + BATCH_SIZE);
// 只把这一小批数据转化为界面元素并添加
appendBatchToDOM(batchToRender);
renderedCount += batchToRender.length;
// 如果还有数据没显示,就继续保留“加载更多”按钮
if (renderedCount < allConversations.length) {
showLoadMoreButton();
} else {
hideLoadMoreButton();
}
};
// 页面加载时,只执行一次
renderNextBatch();
loadMoreButton.onclick = renderNextBatch;
}HotFix 上线之后,效果立竿见影,MolaGPT 页面的崩溃问题立刻消失,在部分移动设备上的卡顿也大幅减轻。
意识到搜索功能的坑,重构搜索逻辑
治标之后,必须治本。我意识到我必须彻底重构侧边栏的整个交互模型,特别是搜索,因为我突然发现如果我表面上懒惰加载历史对话但如果说还是用之前的搜索逻辑,那么就算我改动了基本的渲染逻辑,用户只要一搜索,标签页估计又会崩溃。之前的搜索逻辑实在是太过于短视和粗暴了。
class UIController {
// ...
filterConversations() {
const query = this.elements.searchInput.value.trim().toLowerCase();
const searchContent = this.elements.searchContentCheckbox.checked;
if (!query) {
this.renderFullConversationList();
return;
}
const allConversations = chatHistoryManager.getAllConversations();
const filteredConversations = allConversations.filter(conversation => {
// 标题匹配(粗暴,但是相对较快)
const titleMatch = conversation.title.toLowerCase().includes(query);
// 内容匹配(粗暴,并且内容多的时候极慢!)
let contentMatch = false;
if (searchContent) {
// 对每条对话的完整历史记录进行字符串化和搜索,这是一个非常耗费CPU的操作,阻塞UI。
const historyText = JSON.stringify(conversation.history);
contentMatch = historyText.toLowerCase().includes(query);
}
return titleMatch || contentMatch;
});
// 使用过滤后的结果,同步地重新渲染整个列表,还包括为每个结果动态生成摘要,这里又增加了不少 DOM操作
this.renderFilteredList(filteredConversations, query);
}
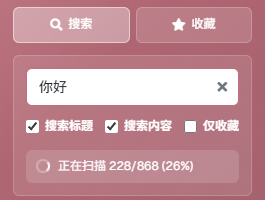
}在旧的搜索逻辑中,当你在搜索框里快速输入“思考”两个字时,它会先启动一次对“思”的全局搜索,等这个漫长的过程结束后,再启动对“思考”的搜索,并且旧的方式是让一个线程从头到尾检查所有对话,效率极低。所以在用户输入搜索内容的过程中,候选区域中呈现假死状态;
为此,我设计并实现了一套新的流式处理机制。目标是,无论用户有多少条对话,搜索响应都必须是瞬时的。
class SidebarController {
constructor() {
this.currentSearchToken = 0; // 用于识别最新搜索任务的“Token”
}
async onSearchInput(query) {
// 每次搜索都生成新的Token
const searchToken = ++this.currentSearchToken;
// 先快速在标题里搜索,这个很快
const titleResults = await searchTitles(query);
if (searchToken !== this.currentSearchToken) return;
// 并行搜索
const contentResults = await searchContentInParallel(query, searchToken);
if (searchToken !== this.currentSearchToken) return;
// 只有当Token不变的时候,才更新最终的UI
this.renderSearchResults(titleResults, contentResults);
}
}它包含两个核心思想:
- 线程可被打断:编写新机制的时候我特别考虑了用户的意图总是在变化的问题。举个例子:当你输入“思考”时,它会立刻放弃之前那个对“思”的搜索任务,只专注于执行你最后下达的指令。这确保了只有最终的、最有意义的搜索请求会被执行到底,过程中的所有中间状态都被优雅地抛弃了,界面也因此保持了流畅。
- 搜索可并行:内容搜索是最耗时的部分,它需要深入每一条对话的内部去匹配文字。新的流式处理逻辑会通过浏览器 API 检测当前用户的设备有多少计算核心,然后把庞大的搜索任务拆分成几份,交给这些线程同时去处理。充分利用多核处理器的多线程能力,每个线程并行工作,最终将结果汇总。通过这种方式,搜索速度得到了成倍的提升,而且由于任务被分解,主线程始终不会被长时间占用。
总结
经过这些可以说比较底层的优化,用户的对话就算有成百上千条,页面卡顿的情况也会大幅减少,不过我也建议了用户及时归档或者删除一些已经不需要再访问的对话。
从一个不起眼的视觉更新,导致的部分用户页面崩溃,我才发现我侧边栏这些渲染的 DOM 操作有多复杂,不得不感叹现代浏览器内核的先进程度!不过虽然已经经过优化了,侧边栏的历史对话的基础逻辑依然是 IndexedDB,之后我可能会进一步重写部分的对话历史渲染逻辑,目标是从客观程度上彻底规避复杂 DOM 操作,但是以原生 JS 实现还有点难度,写入 TODO 吧。

发表回复