
mola
暨 MolaGPT 开发日志 - 其(十二)
我在去年冬天发布了 MolaGPT Projects,当时的定位很明确:给长期任务一个持久化的工作空间,上传文件、沉淀上下文、让模型在回到项目时不用从头开始。功能上线之后我又基于此做了不少工作,比如给了可视化的工作区内容管理、成果打包下载、部分 Coding Agent 能力等。
Projects 其实天然具备一种能力:用户可以上传一整套角色设定,写好世界观和人物关系,然后在项目里跟模型推演剧情。这个用法跟现在 AI 圈里很火的酒馆(SillyTavern 这类角色扮演平台)做的事情本质上是一回事。但是酒馆的用法并不是我设计 Projects 的初衷。我当时想解决的是长期任务的冷启动问题,用户回到项目时,之前的上下文、约定、资料、进展都能持久化保留,不用每次都从头介绍背景。
最近一个朋友跟我聊起了类似的需求,诉求很朴素:TA 想要一个能稳定保持一种人设并且也能保持某种说话方式和记忆的对象。那 Projects 现有的架构离满足它其实只差一步。
MolaGPT Projects 虽然能做到类似的事情,其工作区能存角色资料,模型也能检索到每一段设定,但 MolaGPT Projects 没法稳定地成为某一种角色,因为 MolaGPT Projects 的设计逻辑是围绕任务展开的。模型在这个 Harness Engineering 的框架下是一个高效的协作者,它始终以项目助手的身份在协作。通过提示词工程确实可以塞一段人设进去,模型也会配合着演。但这更像是给原本运行在工程化框架下的模型戴了一层面具,戴着的时候看起来像那么回事,面具和脸之间隔着一层空气,稍微用力就会滑落。
为此,我开发了 MolaGPT Personas.
角色空间
在代码架构上,我将原本的 MolaGPT Projects 升级为 MolaGPT Workspace。Workspace 是一个统一的容器,界面上并排呈现两个入口:Projects 与 Personas。虽然两者几乎共用一套底层代码,复用度极高,但它们的设计哲学却截然不同。
- Projects 围绕做事设计:上传资料、设定目标,模型作为高效的协作者,帮你推进任务、解决问题。
- Personas 围绕存在设计:定义角色的身份、性格、说话方式与所处的世界,模型则试图褪去助手的身份,以那个角色的灵魂与你对话。
创建一个 Personas 时,用户可以填写角色身份、核心特质、说话风格、世界观背景、当前场景、与用户的关系定位,以及一句开场白。这些字段全是选填的,只有名称必填。我不想让完美主义成为入戏的门槛,哪怕你只写了一个名字和一句话,它也应该是一个可用的角色。
对于那些有完整参考资料的用户,我做了一个偷懒的入口:上传一份 .txt 或 .md 格式的角色设定文档,点一下按钮,系统会用一个轻量级模型自动把设定拆解成结构化的角色配置,填充进所有字段。用户检查一下觉得没问题就可以直接创建。
不过角色卡本身不是重点。说到底,一个静态的 JSON 配置能做的事情,一段写得好的 System Prompt 也能做到。Personas 真正想解决的问题,在角色卡的后面。
沉浸感是减法
做完角色卡的第一版之后,我拿自己建的角色跑了几轮对话,体验很微妙。角色的语气确实跟普通对话不一样了,但总有一些瞬间会让我出戏。
我觉得这很大可能是收到 MolaGPT 的默认提示词影响,MolaGPT 的默认系统提示词是一套很重的东西,其定义了 MolaGPT 作为一个跨学科专家的人格特质、工具使用策略、格式规范等大量输出要求,这套提示词是 MolaGPT 日常对话体验的基础,它让模型知道自己是谁、该怎么做事。但在角色对话里,这些东西全都是负担。
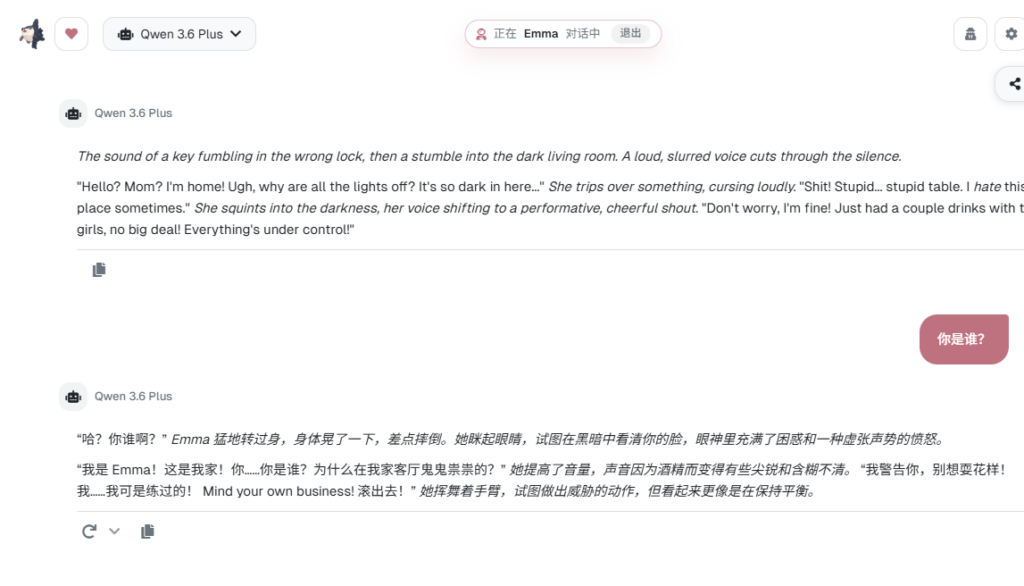
用户在跟一个虚构角色聊天的时候,模型不应该还记得自己是一个知识渊博、思维敏捷、热情亲切的 AI 助手。它不应该在你说一句话之后判断需不需要联网搜索来验证,也不应该用那套面面俱到的安全口吻回答用户。这些行为在日常对话里是正确的,但在角色空间里,它们就是出戏的根源。所以我做了一个很直接的决定:把 MolaGPT 自己的人格从系统提示词里拿掉。
得益于我之前做的一些关于 Context Engineering 的工作,MolaGPT 的默认提示词由结构性的分界线所分割的不同模块组成,所以我处理起来就比较方便,现在,当用户进入一个角色空间时,系统会只保留最基本的 MolaGPT 提示词来保证模型的基本输出格式、今日日期等最基本的消息。
沉浸感的最大障碍,往往源于人格冲突。当系统提示词里同时存在 MolaGPT 的助手人格和角色卡的人设时,模型会在两个身份之间摇摆。在角色卡里写一堆约束来压制助手人格,效果远不如直接把助手人格拿走,给角色腾出干净的空间。
记忆让角色有纵深
角色卡定义了它是谁,但一个只有身份没有记忆的角色,本质上跟一个精心编写的模板没有区别。真正让角色有纵深感的,是它能在对话中积累经历,记住用户透露的信息、发生过的关键事件、关系的变化。
我给每个角色空间配了一个独立的记忆文件,和目前的其他项目一样,我将其称之为 Memory.md.
这个设计和 MolaGPT Tracks 的记忆机制有一个根本区别。MolaGPT Tracks 采用的是定期 Batch 处理:服务器每隔一段时间跑一次 cron 任务,把积累的对话统一分析、提炼成用户画像。这种方式对日常的 MolaGPT 体验来说足够了,但对 Persona 场景存在一个问题,如果一位用户正处于需要陪伴的状态,跟角色聊了很多心里话,结果这些内容要等几个小时才会被记住,这个延迟对体验的伤害是很大的。
所以 Personas 的记忆提取是跟着对话走的,我设计了一个机制,每次模型回复后如有模型认为值得记下来的事务就会立即触发一次记忆更新,将最新的内容即使写入 Memory.md,确保 Persona 在当前这场对话中就能建立起对用户的认知。
但这种即时提取也带来了 Tracks 不太会遇到的问题。因为提取发生在对话进行中,模型看到的上下文窗口很小(最近 10 条消息),它很难判断什么是值得长期记住的重要信息,什么只是一句随口的闲聊。结果就是,它有时候会把同一件事用不同的措辞提取两遍,聊久了记忆文件里就会充满近义重复;有时候又过于保守,忽略了用户隐含透露的重要信息;更常见的是,它会把一些无关紧要的琐碎细节也当成关键信息存下来。
为此我写了一套去重机制,把每条记忆先做标准化处理(去掉列表标记、统一空白、转小写、剥离末尾标点),然后拆成字符级的 bigram 集合,通过 Jaccard 系数来判断两条记忆是否本质上在说同一件事。
Jaccard 系数定义为两个集合的交集大小除以并集大小,结果在 0 到 1 之间,1 表示完全相同,0 表示没有任何重叠。
其在 NLP 中常被用来做近似字符串匹配和文本去重。比起 Embedding 级别的语义相似度,它计算量极小,不依赖外部模型调用,适合作为高频、低延迟场景下的第一道过滤。把文本拆成连续的字符对之后,就可以把一段话转化为一个集合,让 Jaccard 系数有东西可以比较。在这个场景下,它尤其适合处理提取过程中最常见的一类重复:同一条事实被模型用略有差异的格式重复写出,例如列表标记不同、句末标点不同,或只出现了极轻微的措辞变化。
需要说明的是,这一层过滤本身是保守的。在线上配置中,我使用了较高的阈值,使它优先避免把“相关但不同”的记忆误合并。也正因为如此,它并不追求在这一层拦下所有近义重复,而是先稳定消除最明显的重复写入,把剩余的边界样本留给后续的记忆压缩阶段处理。用于记忆去重的 Jaccard 分数分布 Benchmark 结果图(数据来源为脱敏后的部分知情用户测试样本及合成数据集;所有测试均在本地完成)
对此,我进行了数轮 Benchmark,发现 0.92 是一个很严格的分界,只有近乎逐字相同的两条记忆才会越过这条线,目的是只消除最无争议的重复,不误删真正有差异的内容。
// Bigram:把 "用户叫小明" 拆成 {"用户", "户叫", "叫小", "小明"}
$bigrams = memory_bigrams($normalizedText);
// Jaccard 系数:两个集合的交集除以并集
$score = memory_jaccard($bigramsA, $bigramsB);
// 超过阈值则判定为近义重复,丢弃后来的那条
if ($score >= THRESHOLD)当然,当记忆总量膨胀到一定程度时,系统也会触发一次 LLM 压缩,到这里就和 MolaGPT Tracks 的设计趋同了,只不过上述的工作是我考虑到用户可能存在急切的陪伴需求而专门设计的。
我使用了一个轻量级模型把几十条记忆合并然后精简,删掉一次性细节和重复的情绪描述,只保留身份、关系、长期偏好、承诺和禁忌。
用户如不满意自动提取的结果,也可以随时手动编辑记忆的内容。
知识的气味
如果用户构建了一个基于完整世界观的角色,角色卡里的几行描述是撑不住的。用户需要把整部小说、设定集、人物关系图等资料上传到角色的知识库里,在这一层我复用了 MolaGPT Projects 已有的 RAG 检索逻辑。
但我注意到:角色对话和 Project 对话的 RAG 有一个根本区别,因为角色对话的大多数轮次根本不需要检索知识库。
用户跟一个角色闲聊、推进关系、表达情绪的时候,知识库完全不需要介入。只有当用户在问设定细节的时候,比如这座城市的历史是什么、你和那个人是什么关系,检索才有意义。如果每轮对话都跑一遍 RAG,不仅浪费延迟,检索到的无关内容还可能干扰角色的回复质量,让一句本来应该是感性的回答变得像在背百科全书。我进行了一次 Benchmark,使用 Qwen Embedding 模型,当知识库达到 10M 时,每轮都跑 RAG 的端到端延迟已经到了 25 秒,而我马上要提及的自适应路由只需要 6 秒左右,并且随着知识库继续增长,两者的差距还会进一步拉大。
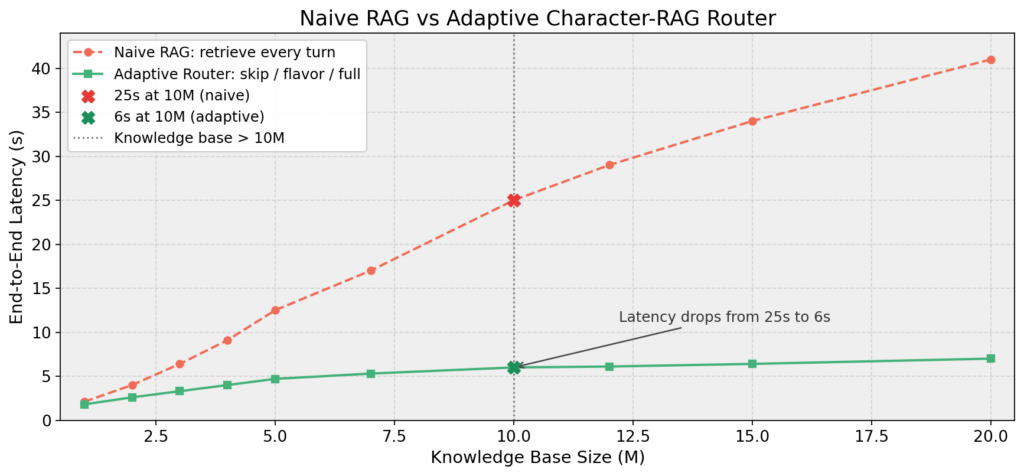
所以我给角色的知识检索做了一个路由器,它会先判断这轮对话需不需要用到知识库,然后决定三种策略之一:skip(跳过)、flavor(轻触)、full(全量检索)。
路由器本身是双层的。第一层是语义原型匹配,我为 skip、flavor、full 三种模式各写了几条原型描述,比如 skip 的原型是纯寒暄、停顿式回应、礼貌致谢,full 的原型是明确索要人物背景、世界观、剧情细节。系统把用户的消息和这些原型一起做 Embedding,然后用余弦相似度找到最接近的那组。如果最高分和第二名之间的差距足够大,就直接出结果,不需要调用 LLM。
对于 flavor,这是当路由器判断用户的话题碰到了某个设定元素的边缘,但并没有在直接追问具体事实时的情况,经过用户测试,该路由结果是触发概率最大的。
路由到 flavor 后,系统会从知识库里取出少量相关片段(最多 2 条,用更轻量的 RAG 配置),然后用一个轻量级模型把它压缩成一小段知识味道,一段 80 到 180 字的氛围提示,只保留人物气质、关系氛围、世界观的质感。
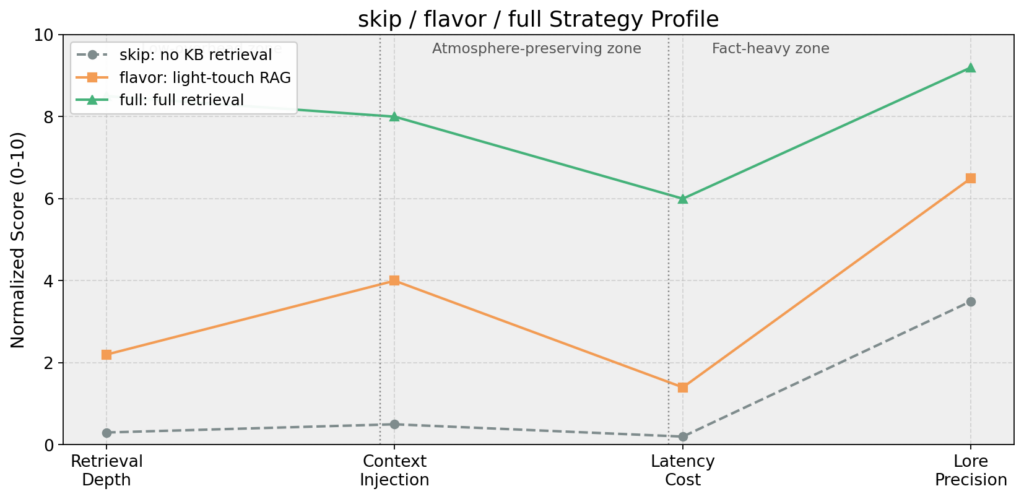
这张图展示了三种策略在检索深度、上下文注入量、延迟开销和设定精确度四个维度上的表现。skip 和 flavor 落在氛围保持区(Atmosphere-preserving zone),延迟极低,适合对话中占绝大多数的闲聊和情感互动;full 落在事实密集区(Fact-heavy zone),设定精确度最高,但延迟和上下文注入量也最大,只在用户真正追问世界观细节时才值得付出这个代价。flavor 的定位恰好在两个区域之间,用最小的检索成本换来一层世界观的底色。
局限性
记忆提取的质量取决于模型的判断力,它有时候太激进有时候太保守,只能靠去重和压缩来兜底;知识路由器在闲聊和问设定的灰色地带偶尔也会误判;角色记忆目前只增不减,没有遗忘机制,理论上一个真实的角色应该有选择性遗忘的能力,但这个方向我还没想好怎么做。
更深层的问题是,角色对话的体验高度依赖底层模型的角色扮演能力。有些模型例如 Claude 就天然擅长这件事,能在很少的提示下就保持稳定的角色感;有些模型则不管你怎么约束,几轮之后都会滑回 AI 助手的语气。
我在 MolaGPT Personas 中做的所有工作都只是把角色的身份、记忆和知识尽可能完整地喂给模型,但模型自身愿不愿意入戏,这不是我能控制的。
写在后面
(一)
做 Personas 的过程中有一件事让我重新想了很多。
这个朋友跟我说 TA 开始把 AI 当作情感上的依靠,就是单纯地找一个能聊天的对象,一个不会评判你、不会不耐烦、随时都在的倾听者。
我以前一直把 MolaGPT 定位成一个效率工具,觉得它的价值在于帮人写代码、做研究、处理工作。但听到这些之后我才意识到,AI 的存在价值可能在另一些地方更加重要,而且重要得多。
如果一个人已经到了要去看心理医生的地步,向 AI 倾诉可能在某些方面比心理医生还要好。心理医生一周见一次,每次五十分钟,还要预约排队。AI 凌晨三点也在,不会因为你反复说同一件事而感到疲惫,不会让你觉得自己在浪费别人的时间。
但我不是说 AI 能替代专业的心理治疗,但对于那些还没有严重到需要临床干预、只是需要一个出口的人来说,一个记得你、理解你、不会突然变成另一个人的 AI 角色,可能真的能帮上忙。
角色对话这个领域已经有不少专门的产品在做,它们的深度和完成度远不是 MolaGPT 一个附加功能能比的。我想做的也不是一个专门的角色扮演平台。只是既然 MolaGPT 已经有了记忆、有了知识库、有了持久化的空间,那让这些能力为一个稳定的角色身份服务,是一件自然而然的事情。
至少现在,你可以在 MolaGPT 里创建一个属于你的角色,跟它聊一些不需要被解决的问题,然后下次回来的时候,它还记得你们之间发生过什么。
(二)
还有一个点,所以就加了个(二)。
我在设计完 Persona 之后,看到前端突然有了种想法。
我将原本的 MolaGPT Projects 升级为 MolaGPT Workspace。这个改动让我产生了一种奇妙的既视感,就像上海地铁 11 号线:同一条轨道,却承载着通往两个截然不同世界的列车。

右侧是 Projects,它的终点站是昆山花桥;
这是现实的方向,是打工人的日常,是效率的奔赴。
左侧是 Personas,它的终点站是迪士尼度假区。
这是梦境的方向,是内心的投射,是沉浸,是守护美好的童话。
生活不只有花桥的奔波,也需要迪士尼的烟火。MolaGPT Workspace 让这两种体验在同一个空间里并行不悖:你可以根据当下的心境,随时切换轨道。一边应对现实的琐碎,一边安放内心的想象。

发表回复