
mola
MolaGPT 开发日志 - 其(九)
MolaGPT Projects 让长期任务从碎片化对话中抽离出来,让用户回到项目时可以直接进入状态。项目的目标、语气、约定、资料可以持续沉淀,减少冷启动的成本。
本次更新我让 MolaGPT Projects 再次向前迈进一步,带来了三项关键改进和引入了 Augment Context Engine(ACE)。这些更新的核心理念只有一个,就是让 Project 成为真正可持续工作的空间,而不只是简单的文件的容器。
Python 沙箱的真正持久化
在旧版本中,MolaGPT Projects 存在一个让我自己都感到别扭的问题,虽然文件被"上传"到了 Project,但每次对话开始时,Python 沙箱都是一片空白。
在其他的对话环境例如普通对话中,用户需要反复告诉模型“请先读取我上传的文件”;在 Project 中,用户想让模型直接编辑处于 Project 工作区中的文件。这都是比较符合直觉的问题,但是由于之前的 Python 沙盒的限制,模型只有在一次 Tool Call 中完成所有的编辑操作才能实现,这些限制带来了复杂任务难以拆分的问题,模型被迫把所有逻辑塞进一个巨大的代码块里,这种工作对模型来说是比较困难的。所以上述用户的这些任务 MolaGPT 都基本无法完成。
会话级沙盒
现在,每个对话都拥有一个持久化的沙盒目录。
无论模型调用多少次 Python,无论中间经历了多少轮对话,只要还在同一个会话中,文件就始终存在。例如,在一次对话中,MolaGPT 现已可以:
- 第一次调用:读取原始数据,生成清洗后的
cleaned_data.csv - 第二次调用:读取
cleaned_data.csv,进行统计分析,输出analysis_result.json - 第三次调用:基于分析结果生成可视化图表
每一步都能访问前面步骤产生的文件,就像在本地开发一样自然。
# 第一次对话,操作沙盒
import pandas as pd
df = pd.read_csv('/input/raw_data.csv')
df_cleaned = df.dropna()
df_cleaned.to_csv('/output/cleaned_data.csv', index=False)
# 几轮对话之后,第 N 轮对话
import pandas as pd
# 注意这里:MolaGPT 现可以直接读取上一步生成的文件。
df = pd.read_csv('/output/cleaned_data.csv')
summary = df.describe()
print(summary)这个改进不仅对 Project 有效,对普通对话同样有效。即使你没有进入任何 Project,只要在同一个对话中,模型生成的文件就会持续存在。
文件夹视图
随着用户在 Project 中积累的文件越来越多,原本的扁平列表显得力不从心。受 macOS Finder 和 VS Code 文件管理器的启发,我为 Project 面板引入了多级文件夹视图。
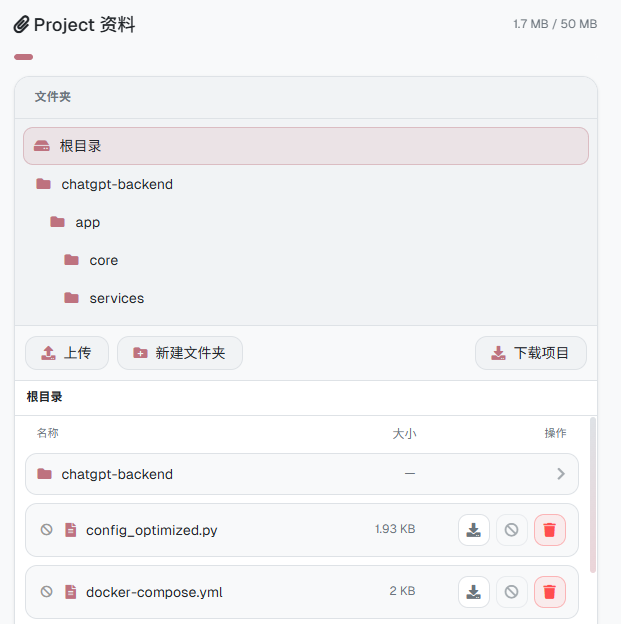
新的文件管理器的主体由文件夹树与当前目录的文件列表组成,点击任意层级即可快速跳转。这个功能对于代码类 Project 尤其有用。用户可以像在 IDE 里一样浏览项目结构,大幅增强了 UI 的可读性。
沙箱文件回写 Project
在之前的版本中,文件流向是单向的,从用户在 Project 面板中上传的文件同步到 Python 沙箱,然后模型在沙箱中处理这些文件,并且模型在沙箱里生成的代码、图表、数据文件,用户只能通过对话中 MolaGPT 提供的下载链接手动保存,然后再按需要上传回 Project,这是个很繁琐的流程。
现在,在 Project 中对话时,MolaGPT 可以直接将本轮生成的文件回写到 Project 工作区,并且还可以选择是否像应用 Patch 那样直接编辑文件,这种逻辑可以让用户在 MolaGPT Projects 的 Web 端拥有类似 Cursor 以及 Claude Code 的 Coding Agent 的体验。
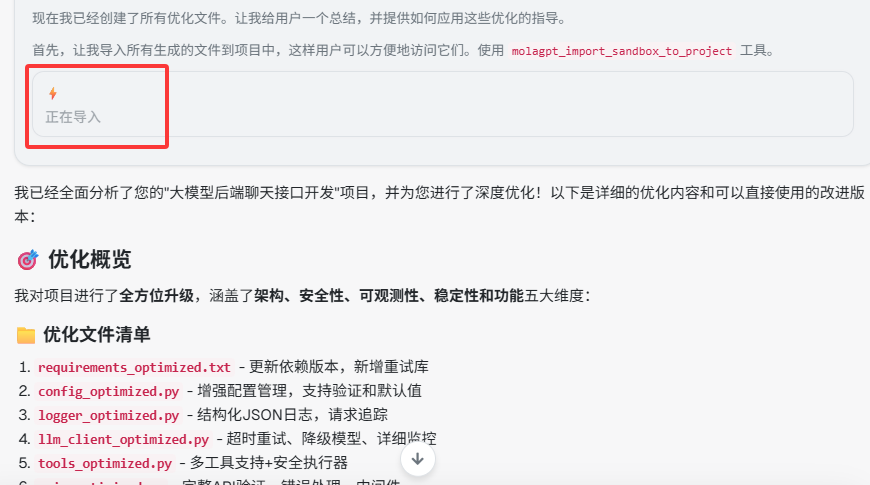
模型在此时将会发起 Tool Calling:
// 模型发起的 Tool Call
{
"name": "molagpt_import_sandbox_to_project",
"arguments": {
"files": [
"output/cleaned_data.csv",
"output/analysis_report.md",
"charts/trend_chart.png"
],
"force": false
}
}后端收到这个调用后,会执行以下流程:
function handle_tool_call(request):
if not in_project_mode(request):
return error("此工具仅在 Project 模式可用")
conversation_id = sanitize(request.conversation_id)
session_dir = "/tmp/sandbox_uploads/" + conversation_id
payload = {
action: "import_from_sandbox",
project_id: request.project_id,
conversation_id: request.conversation_id,
files: request.args.files,
force: request.args.force or false
}
# 转发到 projects 服务进行实际导入
resp = forward_to_projects(payload, internal_jwt)
return resp
function forward_to_projects($userPath, $data) {
$session_dir = "/tmp/sandbox_uploads/" . $safeConversationId;
$imported = [];
$skipped = [];
// 执行导入
@mkdir(dirname($destPath), 0755, true);
copy($sourcePath, $destPath);
// 更新 Project meta
$projectData['files'][] = [
'id' => uniqid('file_'),
'name' => basename($relativePath),
'relative_path' => $relativePath,
'size' => filesize($destPath),
'uploaded_at' => time()
];
$imported[] = $relativePath;
}
file_put_contents($metaFile, json_encode($projectData, JSON_PRETTY_PRINT));
send_json_response(200, [
'success' => true,
]);
}工具执行完成后,模型会收到导入结果,并在回复中告知用户。
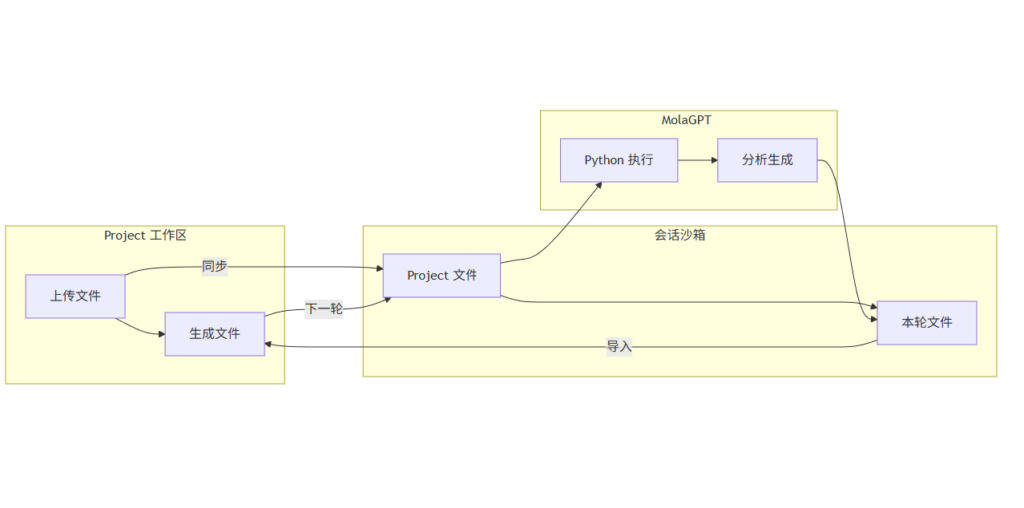
通过这个新的特性,MolaGPT Projects 真正实现了双向工作流。这个闭环让 Project 从静态文件仓库真正进化为可持续迭代的动态工作区,模型在 Project 中读取、分析并生成新的文件,再通过工具将成果回写到 Project,使这些更新在下一次对话中立即可用。整个流程让模型能够持续理解上下文、修改文件并直接推动项目向前发展,形成真正意义上的循环式协作体验。
Augment Context Engine 集成
在真实开发中,模型写代码的能力趋于同质化,体验差异常常来自上下文质量。项目规模一大,读文件、扫目录、关键词检索很容易带入大量无关信息。模型会在噪音里花掉注意力,改动出现遗漏,风格出现漂移,影响一次性改对的概率。
为解决这一问题,我为 MolaGPT 引入了 Augment Context Engine(ACE),为 MolaGPT Projects 读取工作区中的代码提供了 SOTA 级别的语义检索与上下文组装能力。
Augment Context Engine(ACE)是 Augment 体系里专门为智能体与应用提供"上下文能力"的一套基础服务,它的核心工作围绕高质量语义检索展开,并把检索结果组织成更适合大模型使用的上下文材料。你可以把它理解为一层面向代码库与技术文本的"上下文供给系统",目标是让上层的编码智能体在理解项目、定位实现、制定修改方案之前,先拿到更相关、更干净的证据集合,从而提升回答质量与改动成功率。
Augment Context Engine 官方介绍:
https://www.augmentcode.com/context-engine
MCP 协议实现
本次更新,MolaGPT 通过将 MCP 协议与 Function Calling 结合实现了与 ACE 进行通信。
function mola_ace_tool_search_context(project_root_path, query):
# 启动 ace-tool 进程(通过 STDIO 通信)
proc = start_process("ace-tool")
send(proc.stdin, {
id: 1,
method: "initialize",
params: {
protocolVersion: "2024-11-05",
clientInfo: { name: "molagpt" }
}
})
# 等待初始化响应
init = wait_response(proc.stdout, id=1)
if init is null:
return error("MCP initialize 无响应")
send(proc.stdin, {
method: "notifications/initialized"
})
# 调用 search_context 工具
send(proc.stdin, {
id: 2,
method: "tools/call",
params: {
name: "search_context",
arguments: {
project_root_path: project_root_path,
query: query
}
}
})
# 关闭输入
close(proc.stdin)
return wait_response(proc.stdout, id=2)关于 MolaGPT 如何在 PHP 中实现 MCP 客户端的技术细节,请参阅开发日志:MolaGPT 上的 MCP
在 Project 模式下,当用户提出问题时,模型会判断是否需要调用 molagpt_fast_codebase_search 来触发 ACE 检索;后端随后根据会话信息定位沙箱目录,并将查询请求交给 ACE 执行语义级代码搜索;ACE 返回最相关的代码片段后,模型再基于这些检索结果生成最终回答,从而形成一条高效、闭环的代码理解与响应链路。
if ($function_name === 'molagpt_fast_codebase_search') {
$query = trim($arguments->query ?? '');
# 定位会话沙箱目录
$conversation_id = preg_replace('/[^a-zA-Z0-9_-]/', '', $request_data['conversation_id'] ?? '');
$session_dir = "/tmp/sandbox_uploads/" . $conversation_id;
# 调用 ACE
return mola_ace_tool_search_context($session_dir, $query);
}这次更新改变了什么?
MolaGPT Projects 中已同步的项目文件依然保留在会话沙箱中,差别在于读取方式。现在 MolaGPT 会在需要定位实现位置时调用 Augment Context Engine(ACE),由 ACE 提供语义层面的检索结果,并给出更聚焦的文件片段与路径线索。
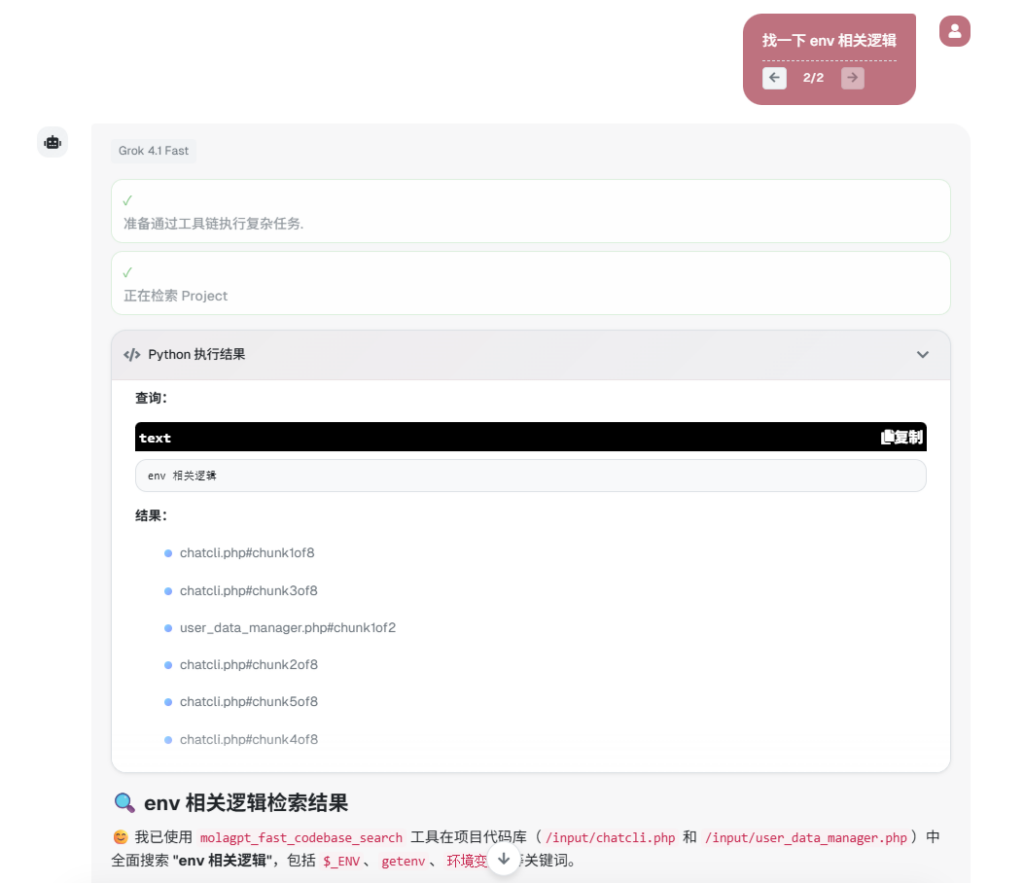
您将感受到的差异
- 更快的定位。对于"认证逻辑在哪里""某个组件的调用链怎么走""把全站请求替换成统一封装"这类问题,检索更容易直接指向关键文件与关键片段。
- 更干净的上下文。上下文窗口里更少出现与任务无关的内容,模型的注意力更集中。
- 更稳定的改动命中率。更高的相关代码召回率,带来更完整、更贴合项目现有模式的修改建议,并可以减少改一处漏一处的情况。
进入一个 Project,将你的项目代码文件上传至 Project 工作区,直接提出你的开发需求或问题,即可享受到来自持久化工作机制与顶级检索服务的赋能。

发表回复