
mola
假设用户上传了一张手写的化学方程式照片,问模型:“帮我配平一下。”如果用户用的是类似我之前开发的 MolaGPT Routes 或者类似的路由器的话,这时候就会有点犯难:这到底算图像识别,还是化学推理?如果系统把它交给一个擅长看图的模型,模型确实能看清图片上写了什么,但如果这个模型逻辑能力捉急,配平就可能配错。换个擅长推理的模型呢?方程式也许能配得漂漂亮亮,但前提是它得先看懂图片里写了什么。要是碰上某些不支持多模态输入的模型,还得有人先把图片里的内容转成文字,再交给它推理。
一开始我觉得问题出在“图片变成文字”这个环节。现实世界里的纸张、笔迹、光线和阴影,被拍成照片之后,必须先转化成模型能处理的文字,才能进入推理过程。看起来,这里横着一道从现实到数据之间的鸿沟。但是,如果视觉模型已经把字符认出来了,说明化学方程式本身已经进入了系统,配平出错,更多是因为这个模型不擅长化学推理。在视觉模型后面接一层文字提取,再把结果传给推理模型,这条路当然能解决很多问题。说到底,这其实是一个 Agent 工程问题,是 Harness 没设计好导致的。
假设未来的模型足够强,它既能看图,又能推理,还能在一张复杂照片里主动放大、裁切、识别细节。那刚才那道鸿沟是不是就消失了?或者说当模型已经能越来越熟练地处理图像、声音、文本、网页、代码和工具返回结果时,我们还能不能说它“没有真正接触世界”?
看见,不等于经历
用户上传的那张纸上,除了化学方程式,也许还有很多东西。某个地方笔迹突然加重了,也许是写的人当时有点烦,也许是快下课了,手上不自觉用力。方程式旁边有一团被涂掉的墨迹,那是一次写错又改掉的痕迹。纸张有折痕和褶皱,可能是被塞进书包里,又在第二天早上皱巴巴地翻出来。
一个足够强的多模态模型,当然可以看到这些。它可以识别笔迹加重,可以指出涂改痕迹,可以判断纸张有折痕,甚至可以根据画面推测这张纸经历过什么。随着多模态能力继续发展,这些细节迟早会被模型捕捉得越来越准。所以说问题不在于它能不能看到,问题在于它看到之后,究竟会把这些东西当成什么。
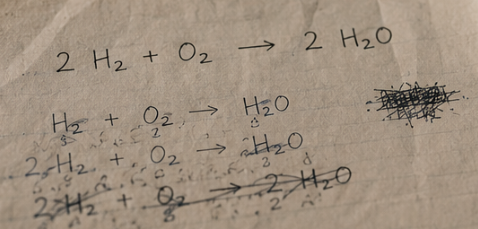
用户问的是“帮我配平一下”。这几个字就是一个提示词,它告诉模型:请你只关心方程式本身。于是笔压、涂改、褶皱、纸张边缘的阴影,都被任务框架排除在意义之外。它们也许都在视觉词元里,也许都被模型编码进了某个高维空间,但在这次任务里,它们没有被允许变得重要。
这有点像我们拿着手电筒走进一间屋子,屋子里当然有桌子、椅子、灰尘、旧玩具和很多已经被遗忘的小物件。手电筒照到哪里,我们才会聚焦在哪里。但人手里的那束光是会乱跑的,一张小时候的照片,一个早就忘在角落里的玩具,有时候手电筒只是无意中扫过去,记忆却会突然自己亮起来。本来只是想找一串钥匙,结果却被一个毫无准备的细节拽回很多年前的某个下午。
大模型从某种意义上来说也是如此,只不过拿着手电筒的人往往不是它自己,更多时候是 Prompt、上下文、系统提示词、工具权限和整个任务框架。它可以识别屋子里有什么,也可以描述照片、玩具和划痕,但如果任务没有允许这些东西变得重要,它们就只是背景信息。哪怕那束光同样扫过那个玩具也不会有谁因此停下来。
即便模型真的把这些细节都说了出来,也不代表它经历了这些细节。它可以说笔迹加重可能暗示书写者情绪波动,但它没有真的握过那支笔。
2024 年年底考研数学那天,临交卷前我突然发现自己算错了一道填空题。那一瞬间的感觉很难描述,手已经开始重新在草稿纸上演算,急切地寻找草稿纸上之前的计算过程,心里却同时在计算剩下的时间。草稿纸上那些被划掉的式子、越写越重的笔画,放到模型眼里都可以被识别成图像细节。但对我来说,那是一段被身体记住的紧张时刻。
同样是一张纸,人看到的可能是作业、考试、焦虑、教室、老师催促的声音,甚至是某个已经回不去的下午。模型看到的是视觉词元,是纹理、边缘、字符、空间关系,以及提示词要求它关注的那部分内容。AI 和世界之间隔着的那层东西,我想把它叫作认知界面。
认知界面
认知界面,指的是现实世界进入 AI 系统之前,必须经过的过滤、翻译和组织机制,一张照片要变成视觉词元,一段声音要变成音频词元,MCP 工具返回的是 JSON、代码沙箱里的执行结果是 stdout,这些东西把现实中的某个片段给翻译成模型可以处理的符号。
如果拆开来看,应该是有两层,第一层是感知入口,它负责把现实转成模型能接收的形式;第二层是行动组织,它负责决定模型在这些输入里该关注什么、该调用什么工具、哪些操作需要人类确认、哪些信息应该写回长短期记忆文档。
在真实产品里,我们常常会发现,同一个模型放进不同的运行时环境,表现会差很多。这里的差异并不神秘,它来自上下文怎样被组织,工具怎样被调用,结果怎样被验证,风险动作怎样被拦截,任务状态怎样被保存。模型本身当然重要,它决定了系统能力的上限;但模型进入产品之后,外层运行时会极大影响这些能力能不能稳定落到具体任务里。
这也是 Harness Engineering 值得被认真讨论的原因。Harness 并不负责把图片变成视觉表示,也不能让一个弱模型凭空拥有强推理能力。它更像是包裹在模型外面的一层运行时系统,负责把模型能力组织成一个可以稳定做事的流程。一个 Agent 能不能持续完成任务,很多时候取决于它能不能正确拿到上下文、选择工具、执行操作、验证结果、处理失败,以及在高风险动作前停下来请求人类确认。
我在做 MolaGPT Routes、Projects、视觉推理、MCP 和代码沙箱时在 Harness 上的考虑:Routes 解决的是用户不想理解模型差异时,系统如何替用户选择更合适的模型和运行策略;Projects 解决的是长期任务里上下文如何持续存在;视觉推理解决的是模型面对复杂图像时,如何通过工程设计的动作复查逐步看清细节;MCP 和代码沙箱解决的是模型如何调用外部工具,把文字里的意图变成真实的查询、计算、文件和图表。
这也是为什么近两年 Agent 产品的差异,很多时候并不只来自模型本身,一个模型放在普通聊天框里,和放进一个有项目文件、长期上下文、工具调用、代码执行、结果校验、权限控制的 Agent 里,呈现出来的能力会完全不同。
所以,Harness 更准确的位置是 AI 接触现实过程中的行动组织层,现实先被感知系统和工具接口翻译成模型能处理的材料,然后 Harness 决定这些材料如何进入任务、如何被调用、如何被验证,以及哪些结果会被写回系统。它让模型更像一个能稳定做事的系统,也让模型和现实之间的接触变得更可控。
但无论 Harness 设计得多好,它仍然是一层被设计出来的工程结构,它能决定模型看什么、做什么、如何验证结果,却很难让模型因为看到什么而自然长出新的在意,图片里的折痕可以进入系统,但系统可能只把它当作背景噪声;一次对话里,用户真正的焦虑可能藏在一句“没事”后面,但如果任务框架只让模型总结待办事项,它就会把那一点颤抖的情绪轻轻放过去。
我们评价一个 Coding Agent 时基本都是在评价模型外面的那层工程界面,Harness 让模型更像一个能稳定做事的系统,也让模型和现实之间的接触变得更可控。但无论 Harness 设计得多好,它仍然是一层被设计出来的界面。它能决定模型看什么、做什么,却很难让模型因为看到了什么而长出新的在意。
人也有自己的认知界面,人的眼睛、耳朵、身体、记忆、情绪都会过滤世界,我们看到的也不是现实本身,而是被生物感官和大脑重构过的版本。会因为一张很多年前的合影,在某个普通下午突然想起一段已经变得很远的关系,我们人的认知界面会被生活不断改写。
AI 没有这种生活,它的界面由模型架构、Prompt、上下文、工具权限和系统设计组成,这套界面可以被优化、被更新、被安全加固,也可以被接上越来越多工具。但它通常没有从一段不可重来的人生里慢慢长出自己的偏执、牵挂和遗憾。它关心什么,很多时候是别人告诉它该关心什么。
越来越像,越来越容易误会
MCP、沙箱,或者像 OpenClaw、Hermes 这样的项目,看起来都在让模型更接近现实:调用外部服务,把某些想法变成真实动作。代码从文字变成了行为,模型似乎也从一个回答者变成了执行者。这正是 Agent 让人兴奋的地方,模型开始替你做一点事,帮你解决问题。它能自行串起一整条流程,很多过去只能停留在对话框里的东西,现在终于有机会落到现实里。

但这并不意味着它真的触碰到了世界,它只是隔着一层又一层接口,在世界表面留下了结果。它可以发出一条微信回复,但不会在发送之后反复想“我刚才那句话是不是说重了?” 它可以帮你整理一段旧照片里的回忆,却不会因为看到照片里的人老去而沉默。工具让 AI 拥有了手,但没有给它身体;记忆让 AI 像是认识你,但没有给它人生。
我之前的文章提过好几次,Agent 一旦获得执行权限,风险会沿着能力扩张的路径同步扩大,让 Agent 有用的,正是让它危险的同一个特征,自主性。我想再补充一点:AI 越来越牛,我们会不会很容易产生一种错觉,觉得 Agent 乃至 AI 本身,是不是也越来越接近活着?
它能记住你,能安慰你,能模仿某种语气,能在角色空间里陪你聊天,能调用工具替你完成任务。它的表现越来越像一个拥有经验的对象,可这种“像”本身,恰恰是最虚无的地方,像经历,不等于有经历;像理解,不等于曾经痛过;像在意,不等于真的舍不得。
不过最近兴起的具身智能正在让这个问题变得复杂,当机器人在物理世界里行走、碰撞、抓取物体,通过摄像头、触觉传感器、力反馈和环境交互不断修正自己的策略时,它确实拥有了比今天聊天模型更丰富的感知和行动闭环。未来的 AI 会拥有越来越多进入现实的接口,也会在越来越多物理反馈中调整自身行为,它们会比今天的模型更能感知环境,更能行动,更能从行动后果里学习。
不过话又又又说回来,这种是对物理规律的适应,另一种属于我们人类的是在生命时间里形成的牵挂。前者可以被工程系统不断逼近,机器人可以学习水会流动,桌子是硬的,摔倒会导致任务失败,抓取太用力会损坏物体。后者则复杂得多,其关乎有限性,关乎一些事情发生之后再也回不到原来的样子。
人类知道疼,不只是因为神经系统给出了痛觉信号,很多时候,疼还意味着羞耻的回忆,摔一跤之后,你记住的可能不是地面硬度较高,而是那天旁边有没有人笑。。。
无法体验世界
AI 无法真正体验世界,这句话听起来有点老生常谈。毕竟 LLM 是权重和代码组成的,例如,模型可以学习“疼痛”这个词在人类语言里通常怎么出现。它知道疼痛常常和受伤或安慰联系在一起。它可以在用户难过的时候生成一段非常合适的话,语气温柔体贴,甚至比很多真人更知道该怎么说。但它没有疼过,没有心跳加速,没有在某个夜里翻来覆去睡不着。它可以写出怀念,却没有离开过一个地方。需要相信这句话的,永远是屏幕前的那个人。
所以我并不想否认 AI 的价值,恰恰相反,AI 是一种极其强大的认知延伸。它可以帮我们处理复杂信息,替我们执行繁琐步骤,能扩展人的视野,增强人的行动能力,只是这些事情的意义,始终要落回人身上,一句安慰有重量,是因为屏幕前真的有一个人需要它。
照片也是如此,模型可以识别一张照片里的每一张脸,判断谁在笑,谁站在边上,光线大概来自哪个方向。它甚至可以根据衣着、背景和画质推测年代,写出一段很像回忆的文字。可它不知道那张照片拍完之后,大家各自走向了哪里;不知道有些人后来慢慢不再联系,有些地方后来再也没有回去;也不知道一张照片为什么会在多年后突然变得沉重。对模型来说,一张照片是一组像素。对人来说,那可能是一段关系最后还能被看见的样子。
活过
AI 当然聪明,而且会越来越聪明。可以预见的未来,AI 会调用更多工具,接入更多系统,更加深度地参与世界运转。它会把很多过去需要人亲手完成的事情变得轻而易举,也会在很多时候比人类更稳定、更高效,更像一个永不疲惫的协作者,但它没有在世界里度过一生。
我不想用一种廉价的人类中心主义去安慰自己,说它再强也终究只是机器,那样也太轻松了。我们真正值得认真面对的是:AI 会在越来越多任务上超过人类,也会在越来越多场景里比人更可靠。
AI 可以把很多碎片化的东西整理成流畅的文字,可以让它们看起来更完整、更清晰、更像一个故事。它能把记忆修得更亮,却无法知道人为什么会舍不得那些模糊的部分。我们这一代人造出了能看、能做、能陪的软件或者模型,也给它接上了越来越多通向现实的接口。可无论这些接口多么精密,它依然没有一条需要自己走完、并且只能走一次的人生。

也许这就是我想说的认知界面。AI 触碰世界的方式,是通过感知、符号、工具和反馈;人触碰世界的方式,是活过。

发表回复