
走下云端
暨 MolaGPT 开发日志 - 其(十三)
mola
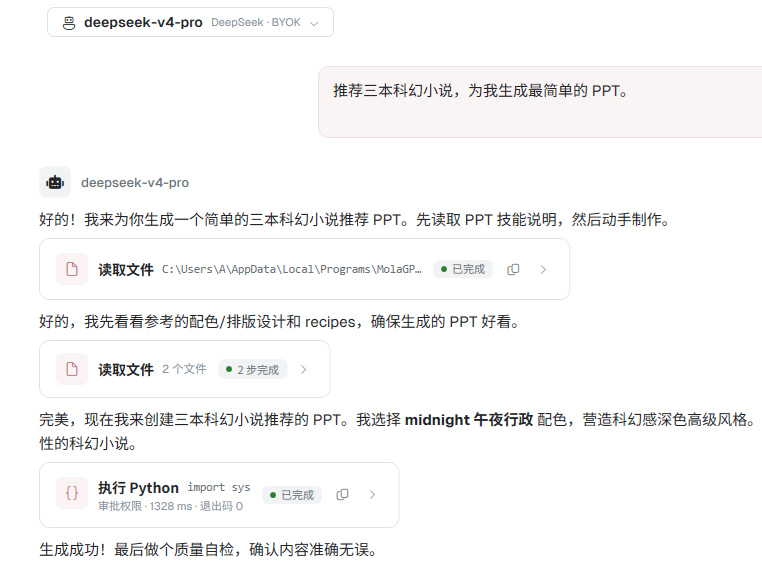
今天,我正式发布 MolaGPT 桌面端,这是 MolaGPT 第一次真正走出浏览器和服务器端侧沙箱的尝试。
在此之前,MolaGPT 的所有能力都发生在 Web 里。用户上传文件,模型读取文件,模型生成结果,用户再把结果下载到本地。它可以搜索,可以记忆,可以通过 Python 沙箱处理文件和生成图表,但它始终无法直接接触用户电脑上的工作目录。浏览器给了 MolaGPT 一个安全、方便、跨平台的运行环境,也给它划下了一条很清晰的边界:模型可以理解你的任务,却不能真正碰到用户的机器。
介绍 MolaGPT Desktop
MolaGPT Desktop 是一个运行在 Windows 上的本地客户端,这是 MolaGPT 向本地工作流伸出的一只手,让原本发生在云端的判断,能接上发生在用户机器上的执行。
MolaGPT Desktop 支持两种运行模式:MolaGPT Chat(MolaGPT 账户标准模式)和 MolaGPT Work [MolaGPT 账户+ 本地工具,或 BYOK (自定义 API) + 本地工具]。BYOK 和 Work 模式下,模型可以直接读取本地文件、运行本地 Python 脚本、生成本地产物。MolaGPT Chat 的体验和 Web 端完全一致。
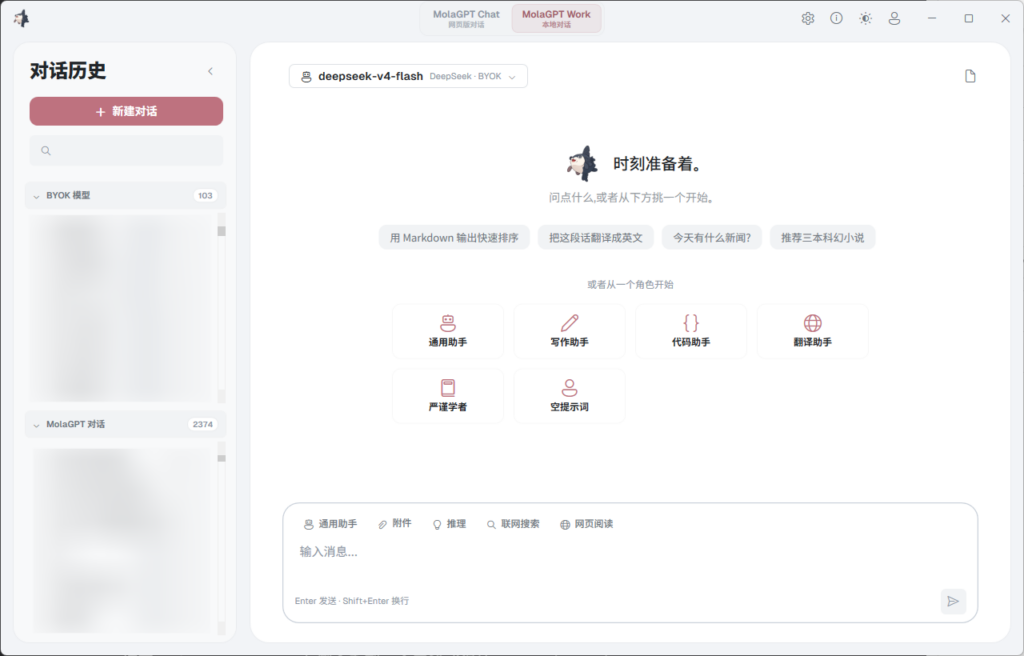
用户通过 MolaGPT Desktop,可以让模型在用户允许的范围内直接读取本地文件、运行本地脚本、生成本地产物,减少人在浏览器、终端和文件夹之间来回搬运的次数,并且用户还可以使用自己的大模型 API 和 MolaGPT Desktop 提供的 Harness 能力来进行工作。
当然,桌面端也意味着更高的权限和更大的风险。模型从只能处理用户上传的文件,变成可以观察本地文件系统,这一步在产品体验上很自然,但在安全设计上必须谨慎。
MolaGPT Desktop 的很多限制看起来保守,其实都是围绕这个问题展开的:既要让模型真正帮上忙,又不能让它在用户电脑上变成一个不可控的黑箱,这一点会在后面着重说明。
BYOK 和 MolaGPT 体系
打开 MolaGPT Desktop,最顶上会看到两个入口:MolaGPT Chat 和 MolaGPT Work,其对应三种完全不同的使用关系:用户是想把MolaGPT Desktop 当作一个自带 API 的本地客户端和 Agent;还是继续使用 MolaGPT 的云端账户能力,但是希望在云端模型和本地文件之间建立一条真正可用的工作通道。
用户通过 BYOK 能力可以在桌面端里配置自己的 OpenAI Compatible、Anthropic、Gemini 或其他兼容接口,把 MolaGPT Desktop 当作一个本地化的多模型客户端来用。对话数据保存在本地,成本、模型来源和数据流向都由用户控制,MolaGPT Desktop 不会通过该渠道搜集任何信息或数据。
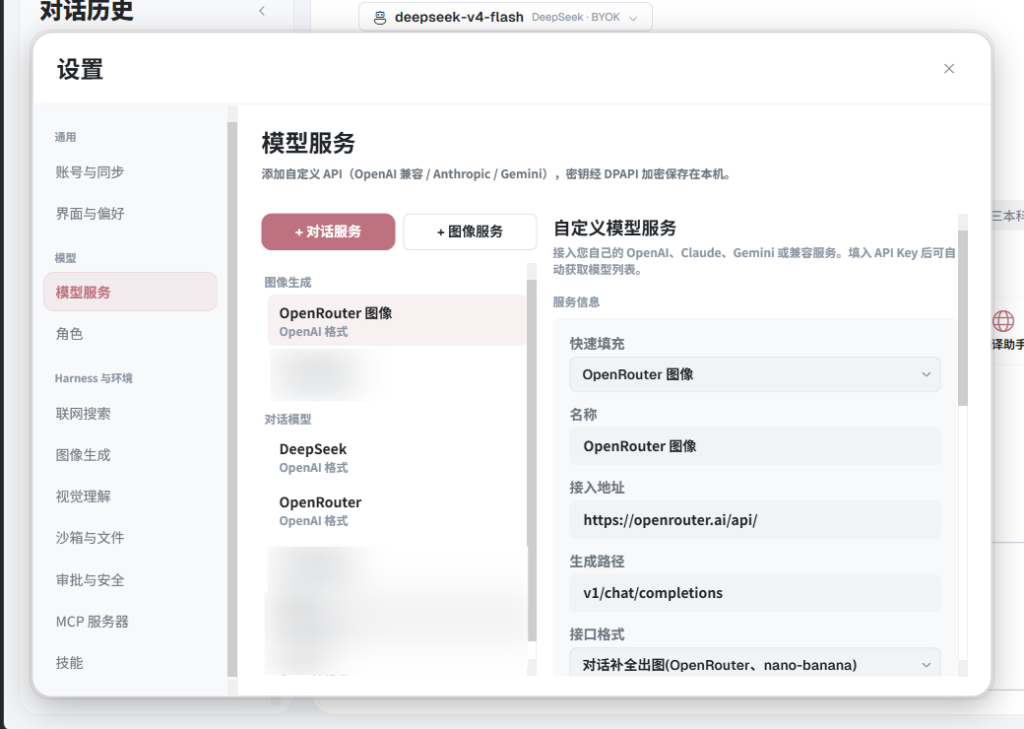
MolaGPT Chat 则是 MolaGPT 账户的标准模式,它与 Web 端共享同一套 Harness:Routes 路由、MolaGPT Tracks、联网搜索、对话历史同步,用户在 Web 端积累下来的使用习惯,可以直接延续到桌面端里。如果只是想继续用原来的 MolaGPT,但是希望它常驻在桌面上,请使用 MolaGPT Chat 模式,用户的所有对话会在多端被自动同步(如果开启了云同步)。
MolaGPT Work 是这次最关键的部分,其把 MolaGPT 的账户能力和本地工具系统接在了一起,MolaGPT Work 模型来源有两种:一种是用户自己配置的 BYOK,一种是通过 MolaGPT 账号使用平台额度。后者主要用于额度计算和身份校验,Work 对话不会并入 MolaGPT Chat 的历史,也不会调用 Chat 模式的对话同步、Tracks 记忆或其他云端个人上下文。
MolaGPT Work
在 Web 端,模型可以理解任务,也可以生成代码,但真正执行的时候,还是要靠用户自己把文件上传、把代码复制到终端、把结果下载回来,再把新的报错或中间产物贴回对话框,AI 明明已经参与了任务,却始终像隔着一层玻璃在帮用户做事,MolaGPT Work 的诞生是我往这方面的做的一点小工作。
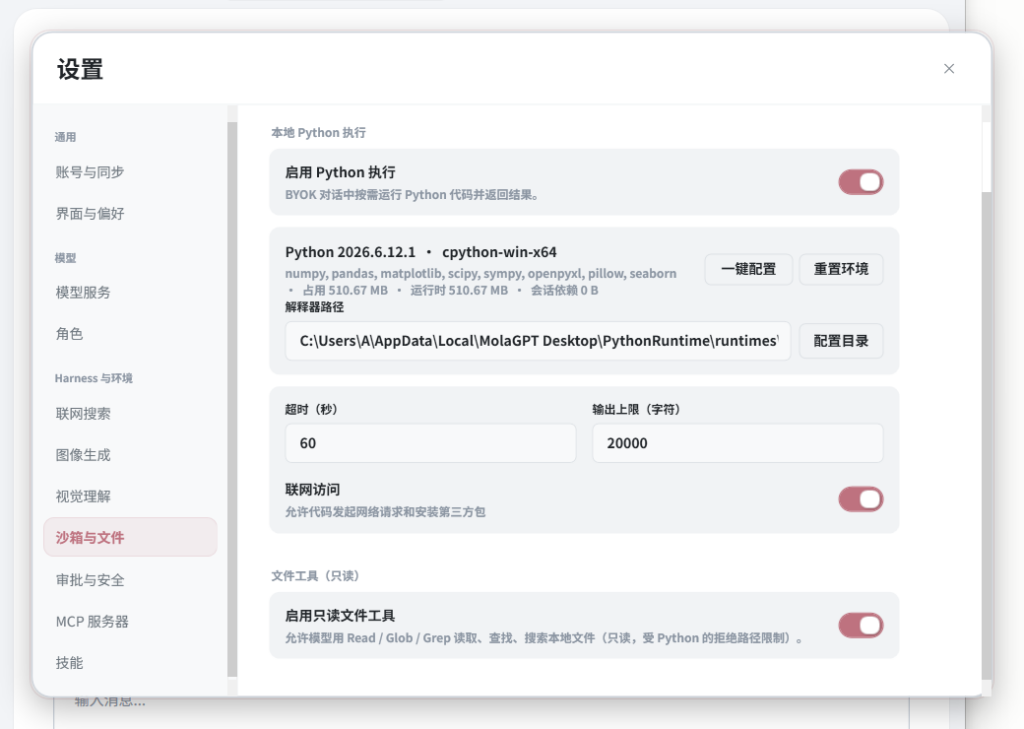
Work 模式最直接的能力,是文件工具,模型可以读取指定路径的文件内容,可以用 glob 匹配搜索文件,也可以在文件里搜索关键词。这一层目前默认是只读的。(本地文件系统和 Web 端上传文件的性质完全不同,我们之后再聊。)
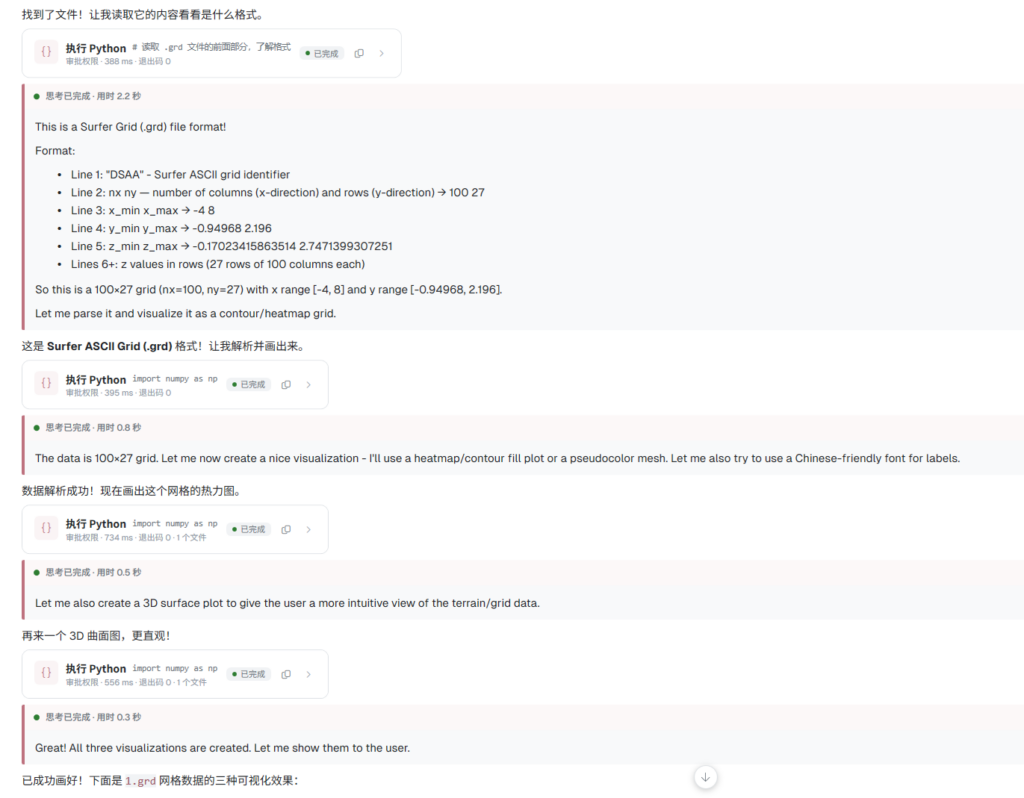
比读文件更关键的,是 Python 执行,你把一个 CSV 丢给 MolaGPT,告诉它做什么,它会自己调用 pandas 做数据清洗,用 matplotlib 生成图表,把产物直接落到工作目录,跑出报错了,它看完报错内容,改掉再跑,不需要用户介入。整个流程里,用户再也不用打开终端,不用手动核对包名,不用在模型和命令行之间来回复制。
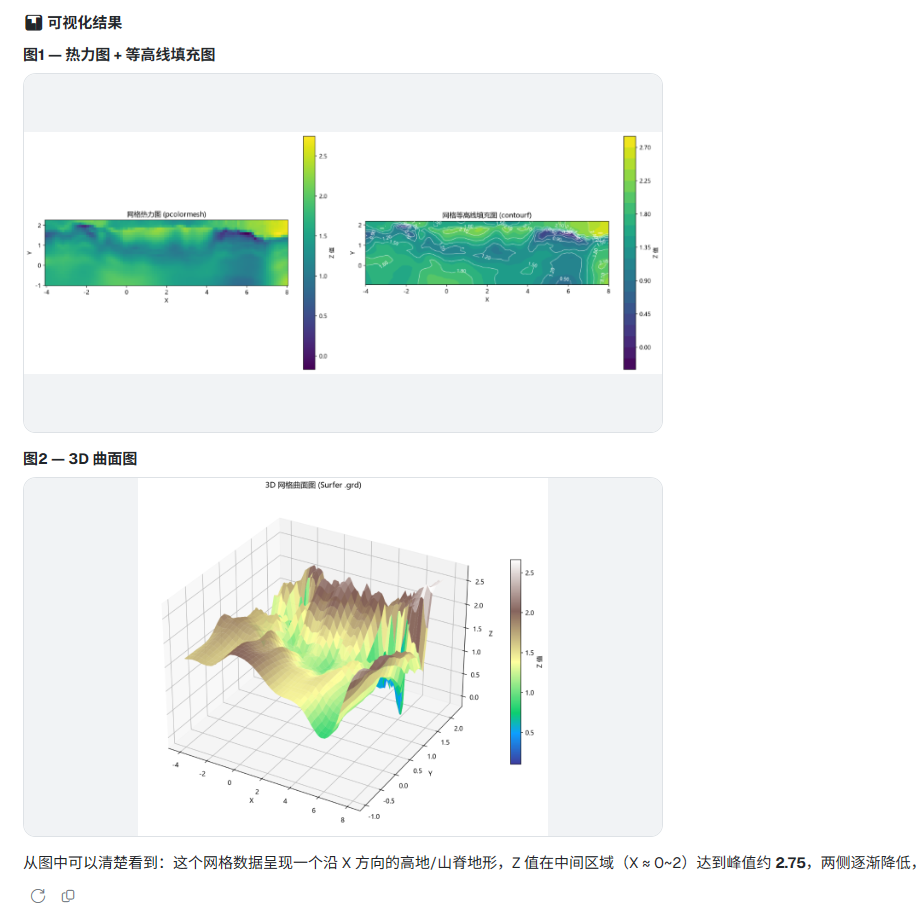
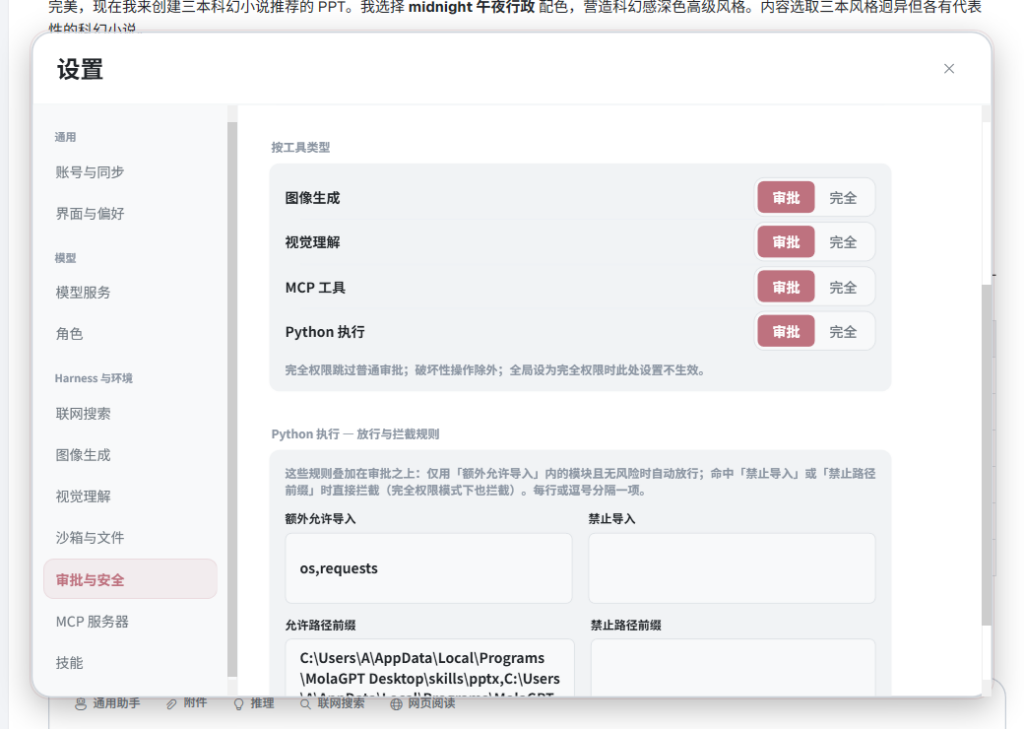
当然,方向盘还应该在用户手里。Harness 能力越强,执行过程就越应该被看见。模型读了哪个文件、跑了什么脚本、生成了什么结果,全部通过工具卡片展示在界面上并且用户可以随时中断,这是我认为本地 Agent 应该有的基本诚实。
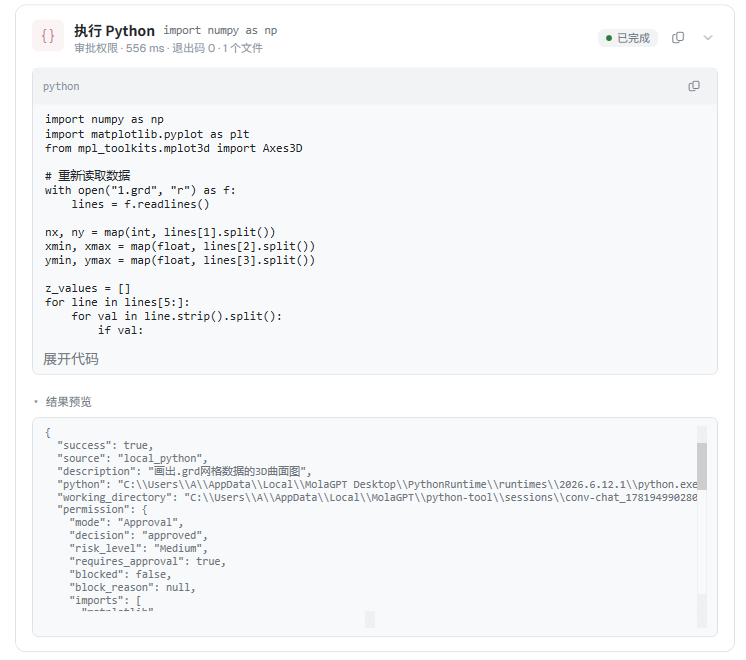
我不希望 Work 模式变成一个黑箱。桌面端的工具调用能力越强,过程就越应该被看见。模型读了什么文件,跑了什么脚本,生成了什么结果,这些东西都应该清清楚楚地摆在界面上。
Skills
Desktop 还引入了 Skills 机制。Skills 是一系列可插拔的专项能力,每个 Skill 都包含一份指令文档,告诉模型针对某类任务应该用什么库、遵循什么写法、产物应该怎么保存。目前内置的 Skills 包括数据分析与可视化、Excel 表格生成与修改、PDF 处理、Word 文档生成、PPT 生成和网页抓取。
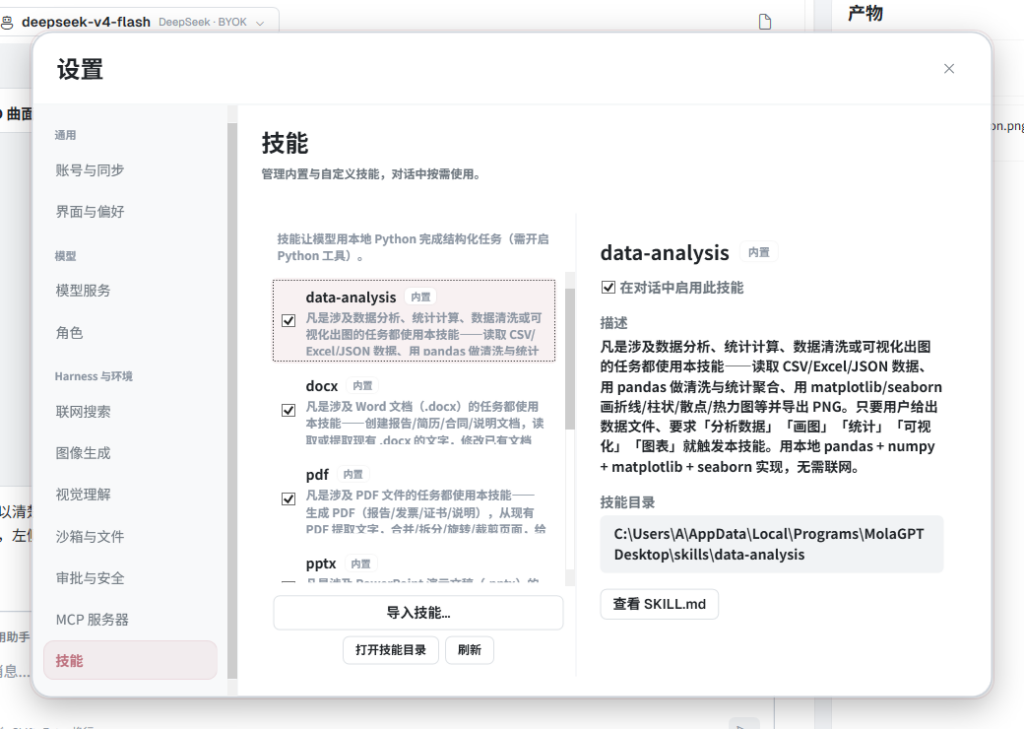
比如数据分析 Skill 会告诉模型优先使用 pandas 做数据清洗,使用 matplotlib 生成图表,并遵循统一的输出规范。Excel Skill 会明确区分 openpyxl 和 xlsxwriter:前者适合读取和修改已有文件,后者适合从零生成结构清晰、带格式和图表的新表格。PDF、Word 和 PPT 也会分别给出对应的库选择和文件生成约束。
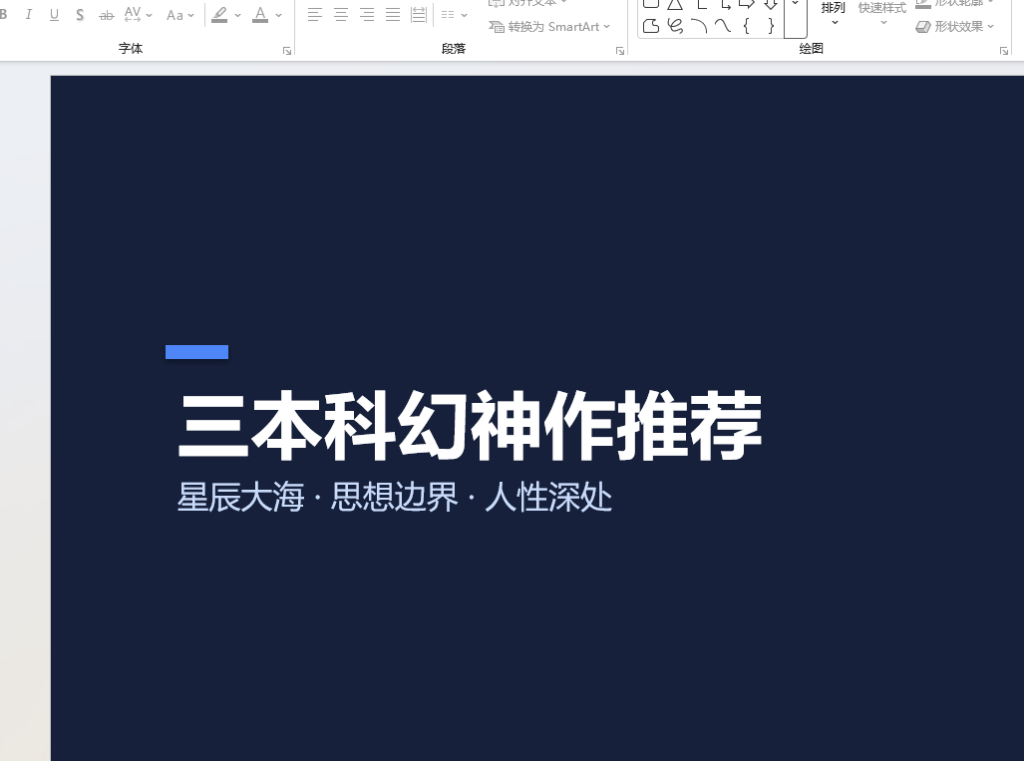
Skills 也支持用户自定义。只要按照规范放到指定目录里,Desktop 就能识别并在合适的时候触发,每位用户的工作流都不一样,有人经常处理科研数据,有人经常整理财务表格,有人经常写周报,有人天天和 PDF 打交道。通用工具只能解决一部分问题,用户可以基于此让 MolaGPT Desktop 具有充分贴近个人化工作流的能力。
权限控制
做 Work 模式之前,我一直做的是 Web 端,相当于根本不会触及到用户的系统,所以当时写 OpenClaw、提示词注入、记忆污染、高权限自治代理的时候,多少还带着旁观者视角,做 Desktop 的 Harness Agent 就不一样了,因为 Work 模式要解决的问题,恰好是让模型从对话框里走出来,接触用户本地的文件、目录和执行环境,我以前在文章里反复提醒别人要警惕的东西,现在开始出现在自己的代码里。
Work 模式的权限设计从一个很朴素的问题出发:如果模型做错了一件事,损失是什么?
在 Web 端,很简单,模型答错了,用户最多浪费一点时间,点一下 Retry 按钮让模型重新生成回答即可。桌面端就严肃多了,模型拥有对用户系统的直接更改权限,如果模型拿着写权限直接改了原始文件,回收站都不一定能救,这是极度危险的。
所以 Work 模式目前的文件工具是完全只读的,模型可以读取文件、用 glob 搜索目录、在文件里匹配关键词,但不能直接修改任何原始文件,因为目前 MolaGPT Desktop 还处于比较早期的版本,我现在正在对文件系统的工具做一些探索,之后也许会陆陆续续添加上编辑类的工具。
这个暂时的取舍让我联想到了我做记忆系统时一直在想的问题:一个能记住一切的 AI 应用,如何才能不令人畏惧?最后的答案依旧是我先更新出了简单的记忆系统之后过了一段时间之后得出的:透明和控制,把记忆的开关和清除权交还给用户。
Work 是同样的逻辑换了个形式,一个能接触本地文件的 AI 应用,如何才能不令人畏惧?答案也差不多,不能让模型在用户看不见的地方做决定,不能让一次判断错误变成不可逆的文件改动。
还有一个就是 Python 执行的问题,因为 Python 跑起来之后也会接触真实的本地环境,Work 模式本来就不是 Web 端那种隔离容,我现在在 Desktop 的做法是把控制点前移。
我认为代码执行过程最重要的是执行请求必须透明可控,所有工具调用都通过工具卡片展示出来,读了哪个路径,跑了什么脚本,输出了什么,报了什么错,这些过程都留在界面上,并且执行风险代码和写入操作的时候必须通过用户审批。
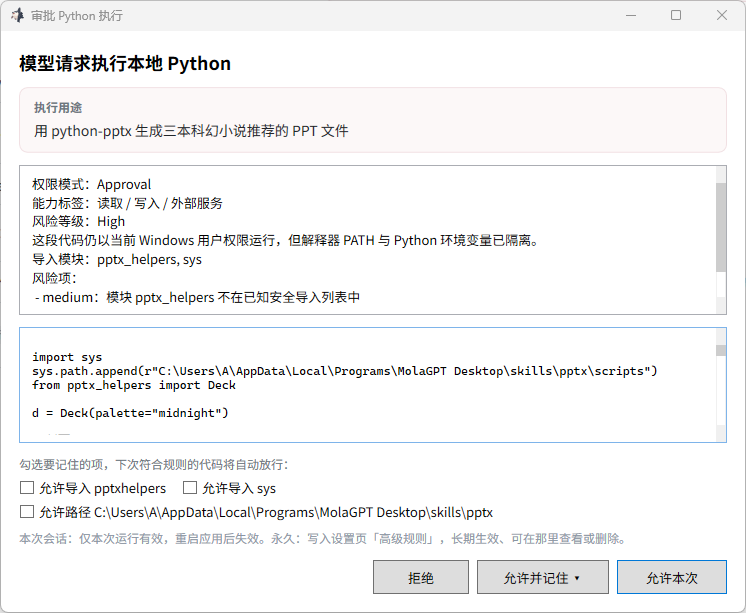
人机协同而不是人机替代,模型接过那些重复繁琐的步骤,但关键节点的确认权留在用户这里。Work 模式给人的感觉应该是AI 可以在你看得见、叫得停、兜得住的范围内帮你处理文件,而不是 AI 接管了用户的电脑,MolaGPT 走下云端,但努力确保不踩过用户的边界。
这条赛道
MolaGPT Desktop 做出来的时候,桌面 Agent 这条路已经很热闹了。
Anthropic 推出了 Claude Cowork,它把 Claude 的 Agentic 能力放到知识工作者的桌面环境里,用户给它一个目标,它可以在本地文件、文件夹和日常应用之间移动,最后返回完成的产物,甚至腾讯的 WorkBuddy 直接宣称自己是 AI Agent 下一代办公范式。
这些产品的共同方向很清晰,AI 正在从聊天窗口里走出来,进入文件系统、编辑器、终端和桌面应用。过去的 AI 更像帮你想,现在的 AI 开始帮你做。
MolaGPT Work 模式也在做这件事,只不过 MolaGPT Work 更像是自然生长的。因为诸如 Claude Cowork 这种软件,它们更像一个面向知识工作者的桌面交付助手,而 MolaGPT Work 没有那么全面和专精,它更像 MolaGPT 自己往本地长出来的一只手,MolaGPT Tracks 解决记忆的问题,MolaGPT Projects 解决长期上下文的问题,MolaGPT Work 解决的则是最后那层现实隔阂:模型理解了你的任务,却碰不到你电脑上的文件。
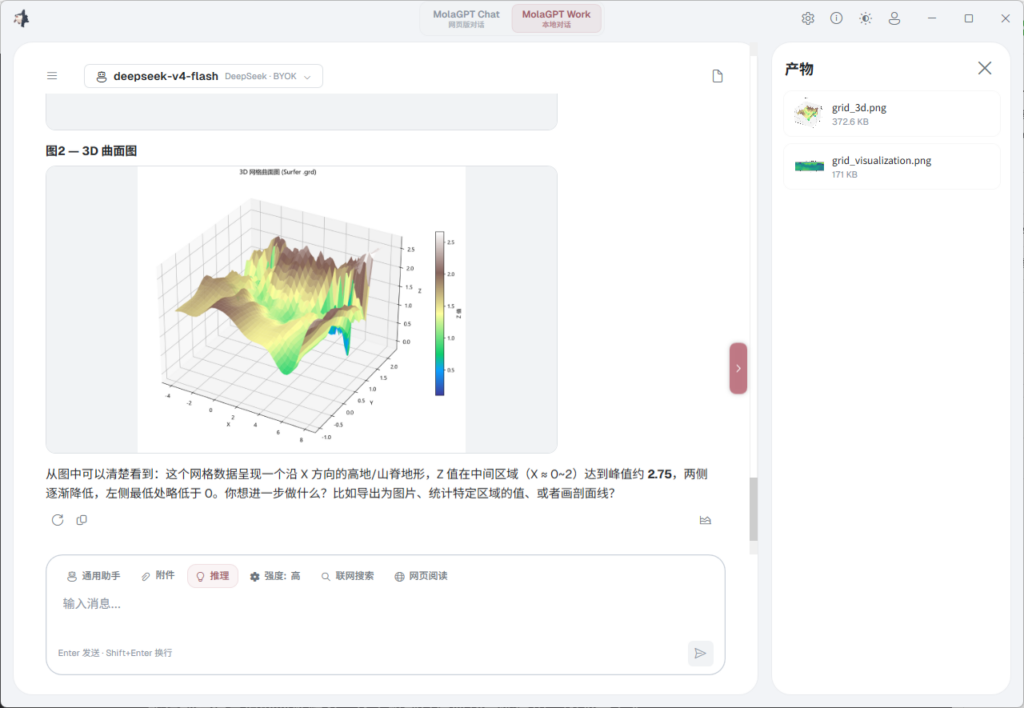
所以它不是一个完全独立的新产品,而是 MolaGPT 向本地能力的自然延伸,已经在用 MolaGPT 的用户,可以在同一个界面里让模型读取本地文件、跑一段分析脚本、生成一个表格或文档,不需要切换到另一套工具,这就是 Work 模式目前最朴素的价值。
用户的工作其实不在对话框里,它在那些命名混乱但逻辑清楚的文件夹里,在一堆 .xlsx、.pdf 里,在反复打开、另存、复制、粘贴、再丢给模型的过程里。Work 模式让 MolaGPT 第一次走到了这些东西旁边。它还不能无所不能,也不应该无所不能,它只是终于可以在你允许的范围内,读到本地文件,跑起本地脚本,生成真正落在硬盘上的产物。
Claude Cowork 和 Workbuddy、Codex 们做得更重,完整度也高很多。MolaGPT 仍然是一个个人项目,这一点不会变。个人项目的节奏大概就是这样:先让它能用,再慢慢让它好用。
云端是个好地方,住久了也想下来走走。
MolaGPT Desktop 和 Work 已上线,支持 Windows 系统。

发表回复