
其(一)
在开发和运营 MolaGPT 时,处理包含代码块、复杂的块状LaTex 以及 CoT 模型的思考过程的 Markdown 格式的流式响应内容是一个大坑。起初,我用简单的正则表达式来解析这些内容,但很快就发现正则匹配像“脱缰的野马”一样难以控制,经常出现识别错误或漏掉内容的情况,把整个 Markdown 区域搞得一团糟。
在开发 MolaGPT 2.3 版本时,闲的无聊但又深受正则所害的我下定决心尝试重构处理和渲染这些 Markdown 格式下的特殊内容。
正则匹配,“去你的吧!”
正则表达式在处理简单的文本匹配时非常高效,且现在网上也有不少正则生成器,规则写起来很是顺滑,但正则在面对复杂的结构时,很容易出现大大小小各种问题。
在我最初的代码中,使用了多个正则表达式来处理不同的内容类型,例如:
// 处理数学公式
const mathMap = new Map();
let counter = 0;
text = text.replace(/(\$\$[\s\S]*?\$\$)|(\\\(\s*[\s\S]*?\s*\\\))|(\$[^$]+?\$)/g, (match) => {
const placeholder = `mathPlaceHolder${counter++}`;
mathMap.set(placeholder, match);
return placeholder;
});
// 保护代码区块
const codeBlocks = [];
text = text.replace(/<pre><code\b[^>]*>([\s\S]*?)<\/code><\/pre>/g, (match, code) => {
codeBlocks.push(code);
return `<!--codePlaceholder${codeBlocks.length - 1}-->`;
});
// 渲染 Markdown
let htmlContent = md.render(text);
// 恢复数学公式
mathMap.forEach((value, placeholder) => {
htmlContent = htmlContent.replace(placeholder, value);
});
// 恢复代码
htmlContent = htmlContent.replace(/<!--codePlaceholder(\d+)-->/g, (match, index) => {
return `<pre><code>${codeBlocks[index]}</code></pre>`;
});这种方法看起来很棒是不是?但在实装后,由于正则匹配的贪婪性,在某些场景下,我遇到了许多能把人搞崩溃的问题。例如,代码块受到莫名其妙出现的数学占位符 mathPlaceHolder 影响从而出现大面积内容恢复时格式被破坏导致的渲染错乱,甚至会破坏整个 Markdown 渲染逻辑导致内存溢出,浏览器卡死。
这些问题多次让我萌生重构捕捉和渲染逻辑,抛弃原有粗放的正则匹配,转向新的技术栈,但是由于我的技术力太低,所以这个事情一直被搁置。直到最近过年闲在家,实在是无所事事,就又开始琢磨这个。偶然一天在网上看到个问题“在 strawberry 这个单词中有多少个字母 R?”似乎 LLM 对这个单词“掌握得不太好”,因为这明明一个很简单的问题,但是各家回答什么的都有,答案有 2 有 3。事实上,这是由 LLM 的技术路线所决定的。
大多数 LLM 都构建在 Transformer 之上,在设计上,模型会将文本分解为标记,这些标记可以是完整的单词、音节或字母。
例如 OpenAI 的分词器:
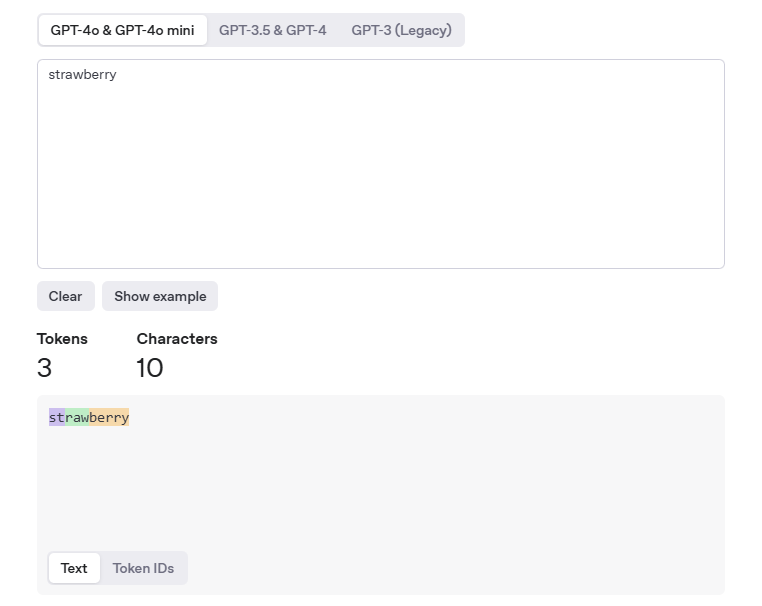
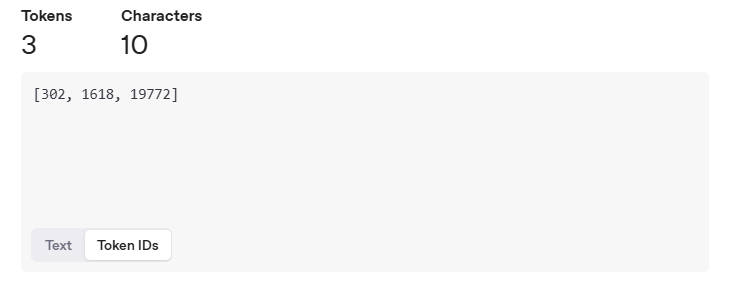
Strawberry 在 OpenAI 模型中的表示是 3 个 token:
[302, 1618, 19772]
这个逻辑会根据先前的单词或标记给出的上下文来预测序列中的下一个单词或标记是什么。这尤其适用于生成不仅连贯而且了解其上下文的文本。但是,它并不真正适合需要精确计算某些内容或推理单个字符的目的,当执行字符计数任务时,模型需要逆向工程分词过程:既要理解"berry"包含两个 r,又要记住"straw"部分已有一个 r。这种跨 token 的推理能力,正是当前自回归预测架构的短板,这也正是这种“窘况”出现的原因之一。
受这个问题启发(其实我也不知道为什么我看完这个问题后会突然有想法去弄这个分词器来替代正则匹配,我写的这个 Tokenize 函数可能只有名字和上面的问题有关联了,但就是看到这个问题后才想到的... 可能这就是 INTP 吧 hhh),我在思考是不是可以用这样的一种分词方式来识别特殊内容的分隔符。
针对上述问题,经过几天的构思和学习,我设计了一种基于分词解析的方法,避免了正则表达式的贪婪匹配问题,并提高了解析的稳定性。其核心思想是逐字符遍历文本,构建结构化的令牌,以确保不同类型的内容能够被精确解析。
核心重构思路
Tokenize 的核心思想是通过逐字符扫描文本,结合类状态机的设计思路,根据当前扫描字符和上下文切换到不同的解析状态。
- 普通文本状态:默认状态,累积普通文本内容。
- 代码块状态:检测到
<pre><code时进入,累积代码块内容,直到检测到</code></pre>。 - 行内代码状态:检测到
<code时进入,累积行内代码内容,直到检测到</code>。 - 思考区块状态:检测到
<think>时进入,累积思考区块内容,直到检测到</think>或流式中断。 - 数学公式状态:检测到
$ ... $,\[ ... \],$$ ... $$,\( ... \)时进入,累积数学公式内容,直到检测到对应的结束标记。(此方式需要对$$\n ... \n$$这种特殊类型的矩阵分隔符做特殊处理,无奈之举...)
类似状态机的形式可以更精准地处理复杂的嵌套结构和流式内容,避免了正则表达频繁的匹配错误。
初始化函数与主循环
function tokenize(rawText) {
let tokens = [];
let i = 0;
while (i < rawText.length) {
}
return tokens;
}tokens:用于存储解析后的 token,每个 token 包含类型(如raw_code、think等)和内容。i:当前字符的索引,参与循环从而实现逐字符扫描文本。
代码块解析逻辑
if (rawText.startsWith("<pre><code", i)) {
let end = rawText.indexOf("</code></pre>", i);
if (end !== -1) {
let rawCodeBlock = rawText.substring(i, end + "</code></pre>".length);
tokens.push({ type: "code_block", content: rawCodeBlock });
i = end + "</code></pre>".length;
continue;
}
}识别 <pre><code ,进入行内代码解析模式,然后继续扫描以匹配 </code> 结束标记,并提取包裹内容,解析完成后存储 Token,更新索引。
startsWith("<pre><code", i):检测是否以<pre><code开头。indexOf("</code></pre>", i):查找代码块的结束标记</code></pre>。tokens.push:将代码块内容作为一个raw_codetoken 存入tokens数组。
行内代码解析逻辑
else if (rawText.startsWith("<code", i)) {
let end = rawText.indexOf("</code>", i);
if (end !== -1) {
let rawInlineCode = rawText.substring(i, end + "</code>".length);
tokens.push({ type: "inline_code", content: rawInlineCode });
i = end + "</code>".length;
continue;
}
}同样地,识别 <code ,进入行内代码解析模式,然后继续扫描以匹配 </code> 结束标记,并提取包裹内容,解析完成后存储 Token,更新索引。
startsWith("<code", i):检测是否以<code开头。indexOf("</code>", i):查找行内代码的结束标记</code>。tokens.push:将行内代码内容作为一个raw_inlinetoken 存入tokens数组。
数学公式解析逻辑(只拿了一种情况来举例)
else if (rawText.startsWith("$$", i)) {
let start = i + 2;
let end = rawText.indexOf("$$", start);
if (end !== -1) {
let content = rawText.substring(start, end).trim();
tokens.push({ type: "math_block", content: content });
i = end + 2;
continue;
}
}识别 $$ 标记,进入 LaTex 块状解析模式,然后读取被包裹内容,并匹配 $$ 结束标记,最后存储解析结果,并更新索引。
startsWith("$$", i):检测是否以$$开头。indexOf("$$", start):查找数学公式的结束标记$$。tokens.push:将数学公式内容作为一个math_blocktoken 存入tokens数组。
P.S. 这里其实有点问题,有时候单个的 $ 也会受影响,到时候得为这种美元符号分隔的 LaTex 内容再做单独处理,或者直接转 \( ... \) 或者 \[ ... \] 也行,到时候再看看。
其他泛化状态
else {
let nextCandidates = [
rawText.indexOf("<think>", i),
rawText.indexOf("<pre><code", i),
rawText.indexOf("<code", i),
rawText.indexOf("$$", i),
rawText.indexOf("\\[", i),
rawText.indexOf("\\(", i),
rawText.indexOf("$", i)
].filter(idx => idx !== -1);
if (nextCandidates.length === 0) {
tokens.push({ type: "text", content: rawText.substring(i) });
break;
}
let nextIndex = Math.min(...nextCandidates);
// 防止死循环:若 nextIndex 等于当前 i,则手动跳过一个字符
if (nextIndex === i) {
tokens.push({ type: "text", content: rawText[i] });
i++;
} else {
tokens.push({ type: "text", content: rawText.substring(i, nextIndex) });
i = nextIndex;
}
}如果当前扫描不匹配以上任意类型,则寻找下一个特殊标记的位置,并将之间的文本作为普通文本处理。
nextCandidates:查找下一个特殊标记的位置。Math.min(...nextCandidates):选择最近的特殊标记位置。tokens.push:将普通文本内容作为一个texttoken 存入tokens数组。- 如果下一个特殊标记的位置与当前索引相同,则手动跳过一个字符,避开标签嵌套导致的死循环问题。
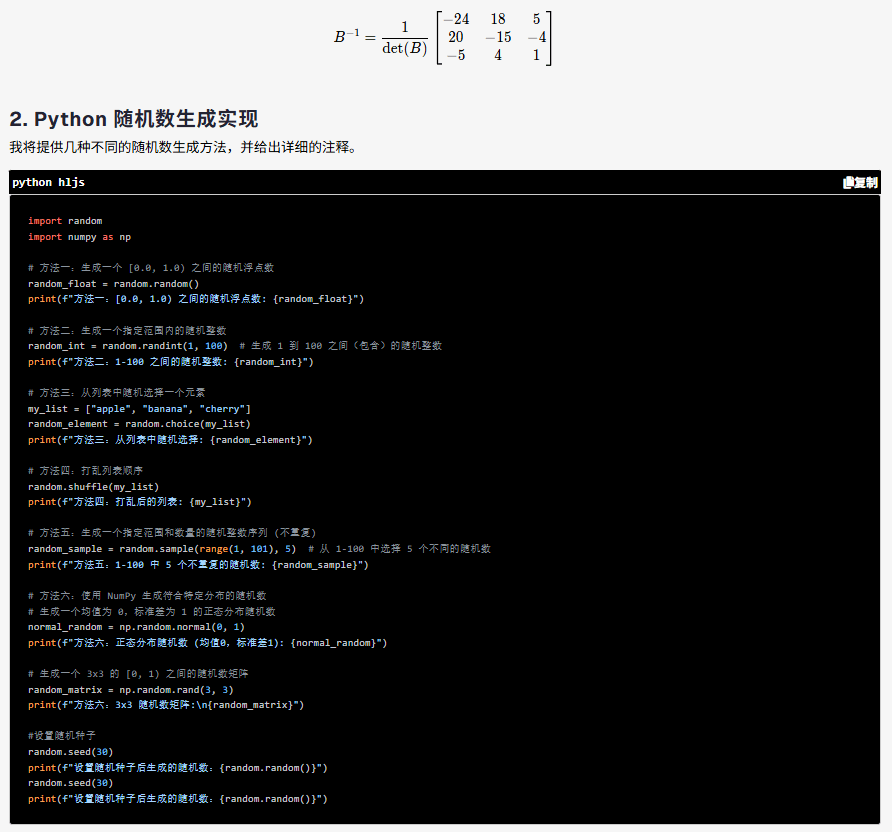
实装效果 (于 MolaGPT 2.3)
LaTex 解析与渲染:

同时进行代码块渲染:
总结
通过从正则表达式到分词器+类状态机机制的转变,我几乎 (“几乎”是因为还有一些顽疾亟待解决)成功解决了复杂内容解析中的诸多问题。新的设计不仅提高了匹配的精准度,解构了解析逻辑,还为之后进一步代码升级提供了全新的底座。

发表回复