
“温良有度”
暨 MolaGPT 开发日记 - 其(八)
几个月前,我构思并为 MolaGPT 开发了记忆系统,并专门花了篇幅介绍了它,在现在,我决定将其改名为:MolaGPT Tracks.
MolaGPT Tracks 通过 RAG 技术和后台的聚类分析,让 MolaGPT 学会了从海量的历史对话中提炼出用户的人格洞察,它开始知道你是谁,知道你的专业背景,甚至能感知你的思维模式。
但这套复杂的记忆系统上线后,我一直在思考一个问题:这些沉淀下来的关于用户的记忆,除了在对话框里提供上下文,还能在哪里发挥温度?
直到最近,MolaGPT 首页问候语上的一个小插曲给了我答案。我之前为了让首页显得不那么单调,曾写过一段非常简单的、基于时间段的问候语逻辑。
比如说,在晚上(19 时至 22 时),MolaGPT 首页的问候语会从我写死的几句话中抽一句显示。
if (hour >= 18 && hour < 22) {
welcomeTexts = [
'晚上好。',
'晚上有什么计划?',
'继续加油。',
'去放松一下吧。',
'还在忙吗?'
'夜猫子你好。'
];
}
这本来是之前 test 的时候感觉可以加入的一个逻辑,我就给加上了,然后编了几条“问候语”,直到上周我收到了 MolaGPT 的一条用户反馈:
“** 刚打开就这样吗?给我干破防了”
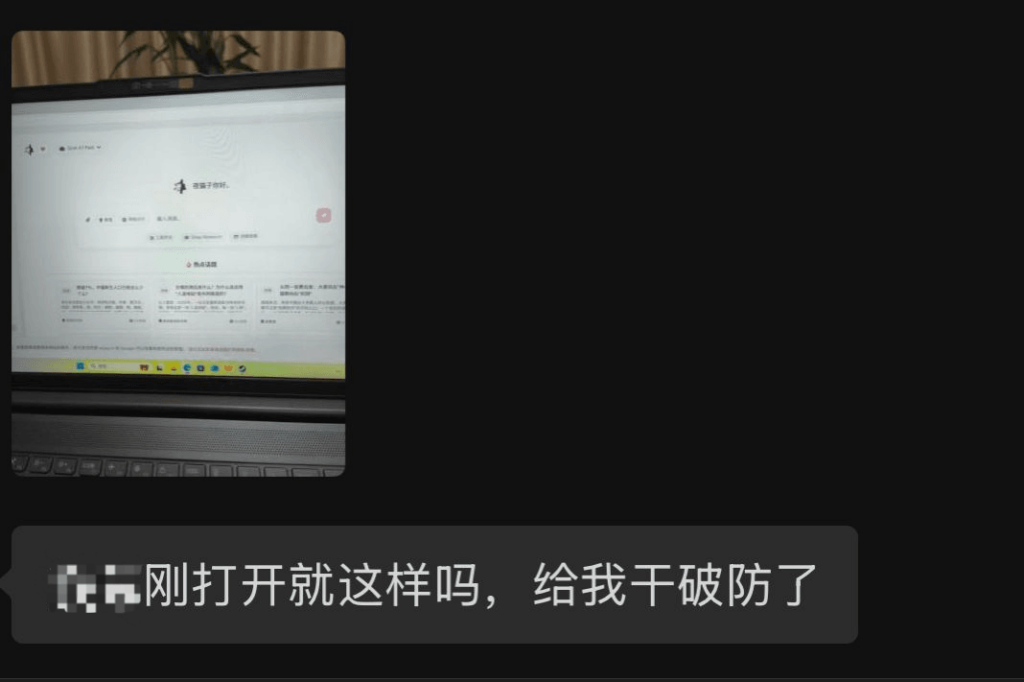
这句反馈让我一下子清醒过来了,我突然意识到在 2020 年代的当下,特别是在这个快节奏、高压力的社会里,用户在深夜需要的不是 KPI 的盘问,而是一个允许停下的“借口”。
并且我作为 MolaGPT 的开发者,最让我感到羞愧的并不是我写了这段问候语生成代码,而是这个逻辑与我之前提到的“双轨记忆”系统产生的巨大割裂感。
明明我的数据库里躺着我对用户详尽的“人格洞察”,我明明拥有如此丰富的记忆,为什么我的首页还在对用户喊着千篇一律的“加油”?
这种割裂感,促成了这次的更新。我决定打通任督二脉,用之前沉淀的记忆,来生成此刻的温柔。
让沉睡的记忆开口说话
在新的架构中,问候语的生成不再只是简单地判断时间,它成为了连接“记忆数据库”与“问候生成器”的桥梁。我几乎废除了那些硬编码的逻辑(对于登录用户来说),转而构建了一套基于 LLM 的动态的问候语生成机制。
现在,当一位开启了个性化记忆的用户打开 MolaGPT 的首页时,后台会:
- 读取人格洞察:从数据库中提取系统对该用户的长期认知。比如:“该用户是资深后端工程师,偏好简洁直接的表达,最近对‘AI Agent’话题表现出浓厚兴趣。”
- 感知即时状态:扫描最近几小时内的对话标题。用户是在高强度 Debug?还是在闲聊摸鱼?
- 动态合成:将上述数据连同用户当前的时间等非敏感信息一起喂给一个专门优化的 LLM.
这意味着,MolaGPT 的每一次问候都是独一无二的,是看人下菜碟的:
- 如果记忆显示你是一位正被论文折磨的研究生,深夜的问候不再是“进度如何”,而是:“学术迷宫虽复杂,但今晚的月光很直白。休息一下吧。”
- 如果记忆显示你是一位刚刚结束工作的程序员,问候可能会变成:“代码跑得很稳,此刻的 CPU 资源只属于你自己的大脑,Enjoy Flow.”
为了确保这份“针对性”不走偏,我在 System Prompt 中不仅注入了记忆数据,更用极大的篇幅定义了绝对不能做什么。我希望问候语的生成逻辑始终保持在一个安全、温柔、可信的范围内。它既要懂得用户的背景与当下状态,又要避免成为一台过度热情、甚至令人不适的机器。
换句话说,记忆赋予了 MolaGPT 个性,而约束则保证了它的分寸。只有在这两者的平衡下,问候语才能真正成为一种“陪伴”,而不是另一种形式的压力。
尊重、透明和约束
在更新 MolaGPT Tracks 时,我曾向用户承诺过对自己记忆的绝对控制权。记忆是有层级之分的,既有无关紧要的闲聊,也有触及灵魂深处的价值观或隐私。如果系统不管三七二十一,把用户所有的深层隐私都抛给 AI 去生成一句问候,那带来的绝不是惊喜,而是惊悚。因此,我必须确保这一逻辑始终运行在一个安全的边界之内。

最低优先级的数据调用
MolaGPT Tracks 可能会存储丰富的人格洞察,但得益于我在开发初期就引入的隐私分级机制,系统在生成洞察时就已经将其细分为身份认知、核心价值、长期兴趣、习惯模式、工作风格、当前项目焦点、阶段性情境以及瞬时兴趣等不同维度。
在此基础上,我为首页问候语的生成接口设计了一套极为严格的过滤逻辑,强制系统执行“最低优先级”的数据调用原则。这意味着,系统被严格限制仅能读取风格偏好、近期显性话题或时间习惯等非敏感数据;而具体的对话内容、个人身份信息、情感状态推断以及政治宗教倾向等高敏感维度的记忆,则被彻底隔离在调用范围之外。
这种克制意味着即使系统掌握了丰富的记忆,它在生成问候时也只会关注一些轻量的信息,比如用户的表达风格或近期的话题,而不会触及隐私或敏感内容。
透明与否定权
在上线个性化问候时,我一直在警惕一种情况:AI 以为它很懂用户,但万一它猜错了呢? 万一它根据某位用户的记忆生成了一句自以为幽默、实则冒犯的话呢?记忆是隐私的,基于记忆的生成更是敏感的。我必须构建一个拥有透明度与用户可控的系统。
在每一句由 AI 生成的问候语旁边,我都放置了一个微小的、不引人注目的"AIGC"标识。同时还会有两个操作按钮:👍(Like)和 👎(Dislike)。
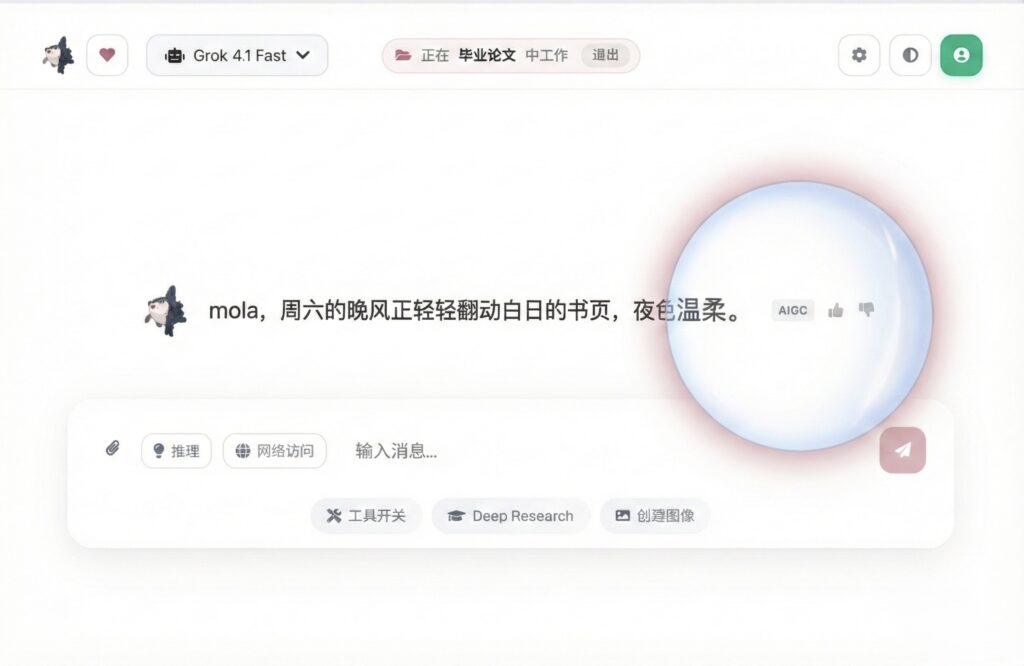
这一设计背后有着三重考量:
- 透明:我必须诚实地告诉用户:“这句话是 AI 根据你的记忆生成的。”哪怕这句问候再像人话,我也不能假装背后坐着一个真人。透明是信任的基石,用户有权知道他面对的是算法还是硬编码。
- 否定权:这是最关键的一点。如果 AI 即使在我的 Prompt 约束下,依然说出了一句让你感到“爹味”或不适的话,用户拥有直接的权利点击“👎”。这个点击动作不仅仅是一个前端交互,它会触发后端接口记录下用户的选择。
- 进化:用户的每一次点击都是对 MolaGPT 的一次微型训练。这些反馈数据会被回流到后台。如果一位用户连续对“幽默风格”的问候点了踩,系统就会在未来自动调整行为。
通过这个评价系统,用户不再是被动接受问候的角色,而能成为问候的塑造者的角色。
写在最后
这几天快期末考了,导师给的任务离 DDL 也越来越近了,但是 MolaGPT 我还是在腹泻更新,没办法,谁叫我脑子里一直有 idea... 这篇文写到这里我觉得我可以替部分朋友向我自己提个问题(因为我自己也有突然有了类似的问题 🤣):为什么你要用如此长的篇幅,去讲述一个或许只在用户眼前停留几秒钟的功能?
-------
跑了个步回来,重置一下思绪,更新一下我对这个疑问的的回答
-------
这次更新,其实讲道理,从技术代码量上看,真不怎么大;但从产品哲学上看,它融入了我对未来人机关系的一些小思考。
我们常说要给 AI 赋予记忆,但记忆的目的不应仅仅是为了提高回答问题的准确率,更应该是为了建立一种默契。
在前不久发布的 MolaGPT Projects 中,我曾着重探讨过如何通过高密度的上下文环境,将 LLM 从“通用对话者”升级为“深度协作者”。那时我追求的是一种“工作上的默契”。我在工作流的不同地方做了工作,尽可能地消除或减少冷启动产生的时间成本,为了减少 Vibe 的培养,为了让用户在回到项目时能感受到 MolaGPT 仿佛从未离开,随时准备好进入工作状态。
但在我看来,默契不应只有一种面孔。
如果说 MolaGPT Projects 是为了让用户“更快地进入工作”,那么今天的个性化问候,则是为了让你“更安心地暂停工作”。
真正的智能助手,不应该只是一个冷冰冰的效率工具,用户一进来就好像看到了 Leader(时刻拿着鞭子催促我们“更快、更强”)一样瞬间一天的好心情都没了。
我通过打通 MolaGPT Tracks 记忆系统,通过严苛的约束,通过赋予用户评价的权利,我希望 MolaGPT 能成为那个在路边长椅上,记得你只喝温水、愿意陪你静静坐一会儿的朋友。
希望今晚,当你在深夜打开 MolaGPT 时,它不再问你“进度如何?”,而是基于它对你长久以来的了解,轻轻对你说一句:
“我知道你最近在攻克难题,但此刻,星光落得很轻,只属于你自己。”


发表回复