
暨 MolaGPT 开发日记 - 其(四)
两个月之前,我为 MolaGPT 推出了 Deep Research 模式并将核心逻辑开源在了 GitHub。在这期间,我收到了一些用户反馈,结合我自己的实际使用体验,我认为旧版 MolaGPT Deep Research 有着十分明显的局限性:纯粹的“搜索—分析”循环无法应对复杂的研究需求,特别是在复杂问题的研究中,这种模式的局限性被成倍放大。
针对此,在新版本 MolaGPT Deep Research 中,它不再是一个独立的“搜索—分析”循环模块,而是一个能够使用多种工具辅助完成任务的智能代理。它的设计理念依然是模拟研究人员的思维过程,但现在它拥有了更丰富的研究手段:不仅能搜索和分析,还能浏览网页、执行代码、生成图表。
虽然内部架构大改,用户的使用方式依然保持不变:在与 MolaGPT 的对话中提及"为我深度研究"或"为我深入分析"等关键词,或是直接点击输入框下方的"Deep Research"按钮即可触发。
下面带来详细介绍。
新版本 MolaGPT Deep Research 实现
旧版本的 MolaGPT Deep Research 是一个相对简单的迭代流程:搜索→分析→总接并提取下一轮关键词→再次搜索,其流程图如下图所示:
新版本在整个研究流程上做了较大的改动,但实际上大体执行逻辑与旧版 MolaGPT Deep Research 差距不大,其流程图如下图所示:
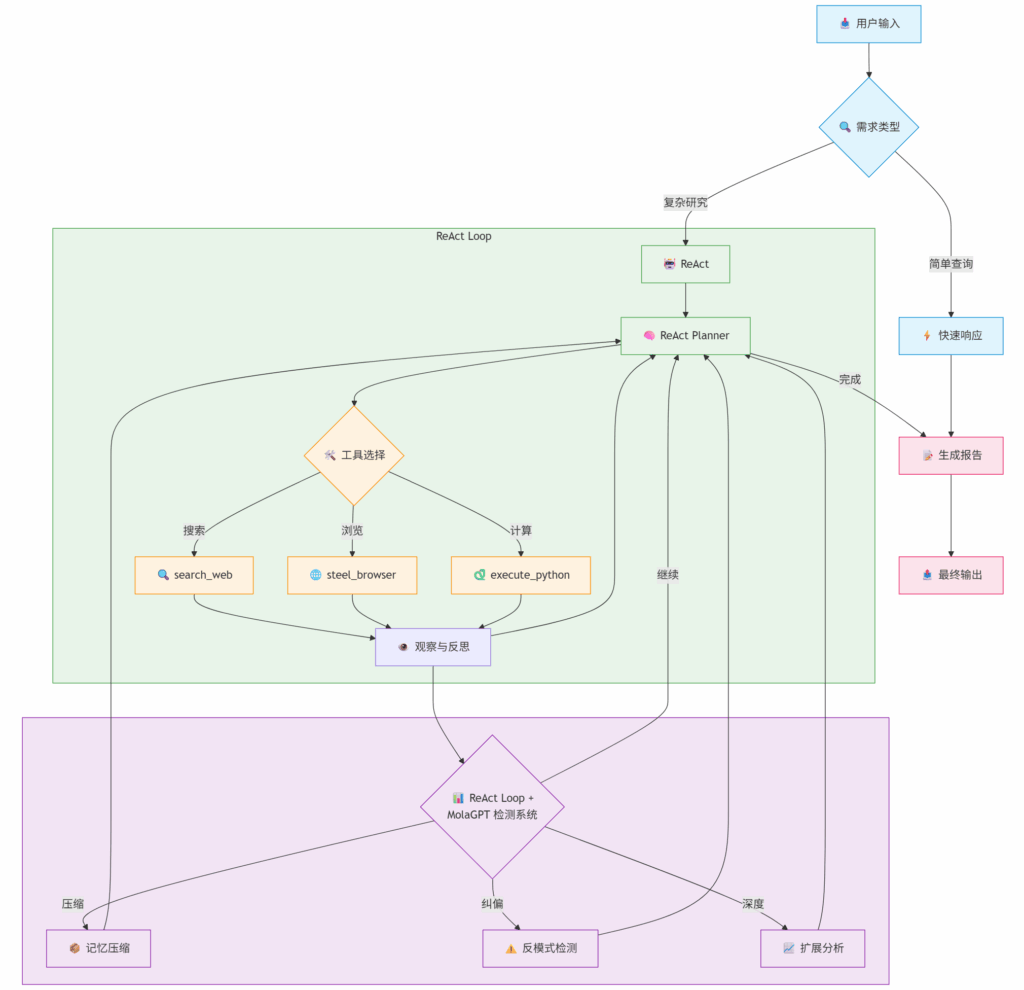
变化 1:ReAct Agent
在新版本中,我为 MolaGPT Deep Research 引入了基于原生 AI Agent 思想的的 ReAct(Reasoning + Acting)框架,在每个深入研究过程中都采用标准的 ReAct 循环:Thought (思考与规划) → Action (执行与等待) → Observation (观察与反思)。
function run_react_agent($goal, $initial_thought_prompt, $max_iterations, $tools) {
while ($iteration < $max_iterations) {
// Thought: 基于目标和历史,分析当前情况
$thought = $planner->analyze($goal, $history, $tools);
// Action: 决定使用哪个工具,传入什么参数
$action = $planner->decide_action();
// Observation: 执行工具,获取结果
$observation = execute_function_call($action['tool'], $action['params']);
// 记录到历史,作为上下文提供给未来参考
$history[] = compact('thought', 'action', 'observation');
}
}在此过程中,新版 MolaGPT Deep Research 可以自动化地按照其需要自由使用 MolaGPT 平台已有的工具:
search_web- 网络搜索工具,用于快速获取信息。steel_browser- 网页深度分析工具,支持多种操作:scrape: 获取完整页面内容screenshot: 获取网页截图extract_data: 提取特定信息screenshot_analyze: 视觉分析
execute_python_code- Python 沙盒,用于数据分析、数值计算和可视化。
并且由于我使用了基于上下文的识别方式,即使 Agent 所使用的模型不支持 Function Calling,也可以正确使用所有工具。
而在旧版 MolaGPT Deep Research 中,Agent 完全无法使用任何工具(如果 search_web 不算的话),一味地机械化地搜集信息是低效的。不断地思考和调整策略。发现新线索时会改变方向,遇到死胡同时会另辟蹊径,信息充分时知道适可而止。这种动态的、自适应的研究过程,正是旧版 MolaGPT Deep Research 所缺失,局限性最大的方面。
变化 2:历史压缩机制
在新版本的 MolaGPT Deep Research 开发过程中,我遇到了一个棘手的问题:当研究进行到第 15 轮、20 轮时,累积的历史记录会变得极其庞大,不仅影响 Agent 的推理速度,还可能超出 Agent 模型的上下文窗口限制。经过反复测试,目前 Agent 所使用的模型当 input 过多时,会出现“上下文溢出 (Context Overflow)”的现象,导致每轮研究的反思结果和下一步操作的结果都完全一致,从而发生研究死循环。
为此,我在整个 flow 中专门设计了一个渐进式的研究历史压缩函数。系统会在第 11 轮时自动将前 10 轮的详细记录压缩成一份结构化的摘要,保留关键的研究发现、使用过的搜索策略和重要的转折点。这个压缩过程会每 10 轮触发一次,确保即使是长达数十轮的深度研究也不超过模型上下文限制,使得整个 flow 保持高效运行。
function compress_research_history($history, $current_iteration, $compression_threshold = 10, &$cached_summary = null) {
// 每10轮压缩一次
if ($current_iteration % 10 == 1 && $current_iteration > $compression_threshold) {
$compress_count = floor(($current_iteration - 1) / 10) * 10;
$history_to_compress = array_slice($history, 0, $compress_count);
// 使用专门的压缩模型生成摘要
$cached_summary = generate_history_summary($history_to_compress);
}
// 组合压缩摘要和最近的详细历史
return combine_compressed_and_recent($cached_summary, $recent_history);
}这个 compress_research_history 函数能在研究轮数到达 10 时,使用专用模型自动对 10 轮的所有研究历史自动压缩,随后注入到之后所有轮次的研究中,保证上下文连贯但又不超过模型的上下文窗口限制。
变化 3:反模式检测
虽然在上文中我已经通过压缩研究历史来尽可能缩短模型的 Prompt,但死循环的问题还是让我头疼。Agent 不断搜索相似的内容,像是在原地打转。在分析了大量的研究日志后,我发现了几种典型的"反模式":
- 重复搜索:连续使用相同或极其相似的搜索词
- 狭窄循环:在2-3个相关主题间反复跳转
- 无效深挖:对已经充分探索的方向继续深入
出现这种情况除了上下文溢出导致的机械重复外,还有可能是因为陷入注意力饱和(Attention Saturation)状态,当相似的研究历史不断累积,模型的注意力机制被大量同质化信息占据,失去了识别新方向的敏锐度。这种现象在学术上也被称为重复退化(Repetition Degeneration),是大语言模型的固有缺陷之一。
为了从根本解决这种问题,我尝试通过加入一种主动的干预机制来打破这种循环。思路非常简单:既然模型自己意识不到陷入了循环,那就让已经写死参数的系统来当一个清醒的“旁观者”。为此,我设计了一个实时的模式检测器,它会持续监控Agent的行为模式。
// 伪代码,仅供参考
$check_search_repetition = function($search_history, $current_iteration) {
// 检查最近 3 次搜索
$recent_searches = array_slice($search_history, -3);
// 统计重复查询
$query_counts = [];
foreach ($recent_searches as $search) {
$key = $search['tool'] . ':' . $search['query'];
$query_counts[$key] = ($query_counts[$key] ?? 0) + 1;
}
// 检测相似度超过 90 % 的查询
// 生成干预
};这个检测器不是简单地比对字符串,而是从多个维度分析 Agent 的研究轨迹:
- 研究广度评估:通过分析搜索关键词的语义分布,判断研究是否过于集中在某个狭窄领域。
- 查询重复度分析:不仅检查完全相同的搜索词,还计算查询之间的语义相似度。如果连续 3 次搜索的相似度超过 90 %,就触发警告。
新系统会实时监控这些模式。当检测到研究可能陷入循环时,会主动提供策略建议并作为前置系统信息注入到下一轮研究过程:“换个角度搜索、尝试不同的工具组合、或者从更宏观的视角重新审视问题”。
这种系统没有强制改变 Agent 的行为,而是通过自然语言从模型认知层面发出提醒,让 Agent 自己意识到问题并主动调整策略。
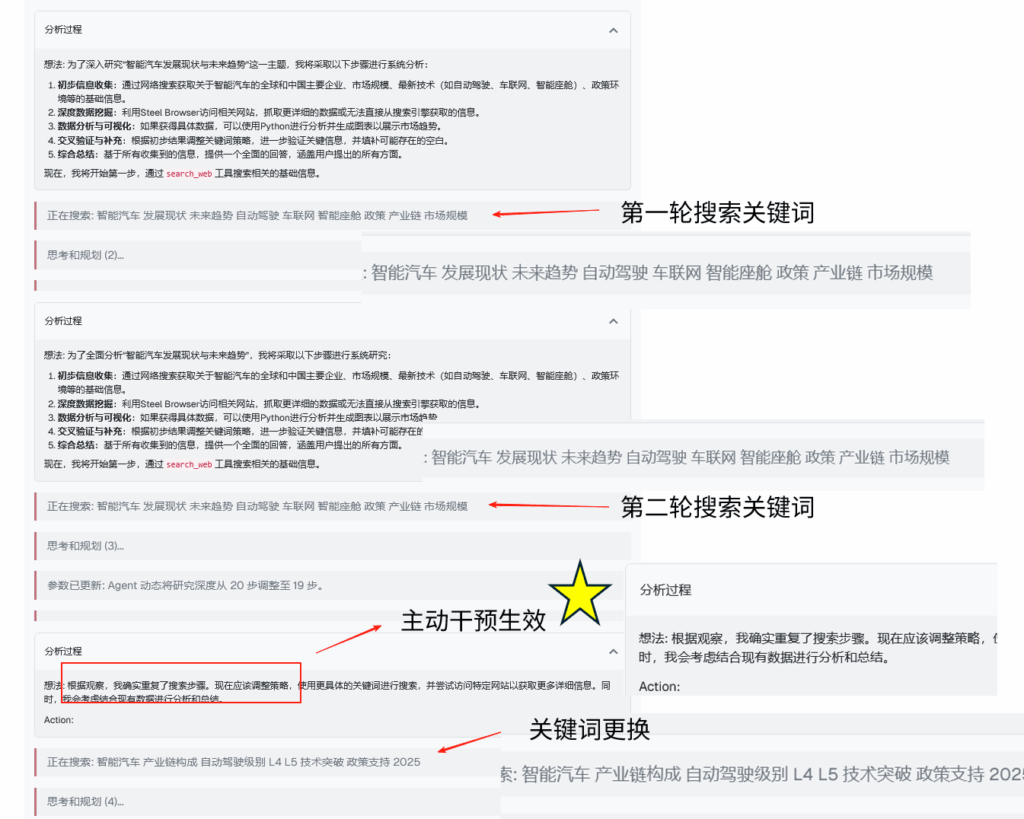
在开发过程中,我对这个系统进行了多次微调,测试结果显示:原本会陷入 20 + 轮循环搜索的任务,现在通常在检测到第 2-3 次重复时就会自动调整方向。
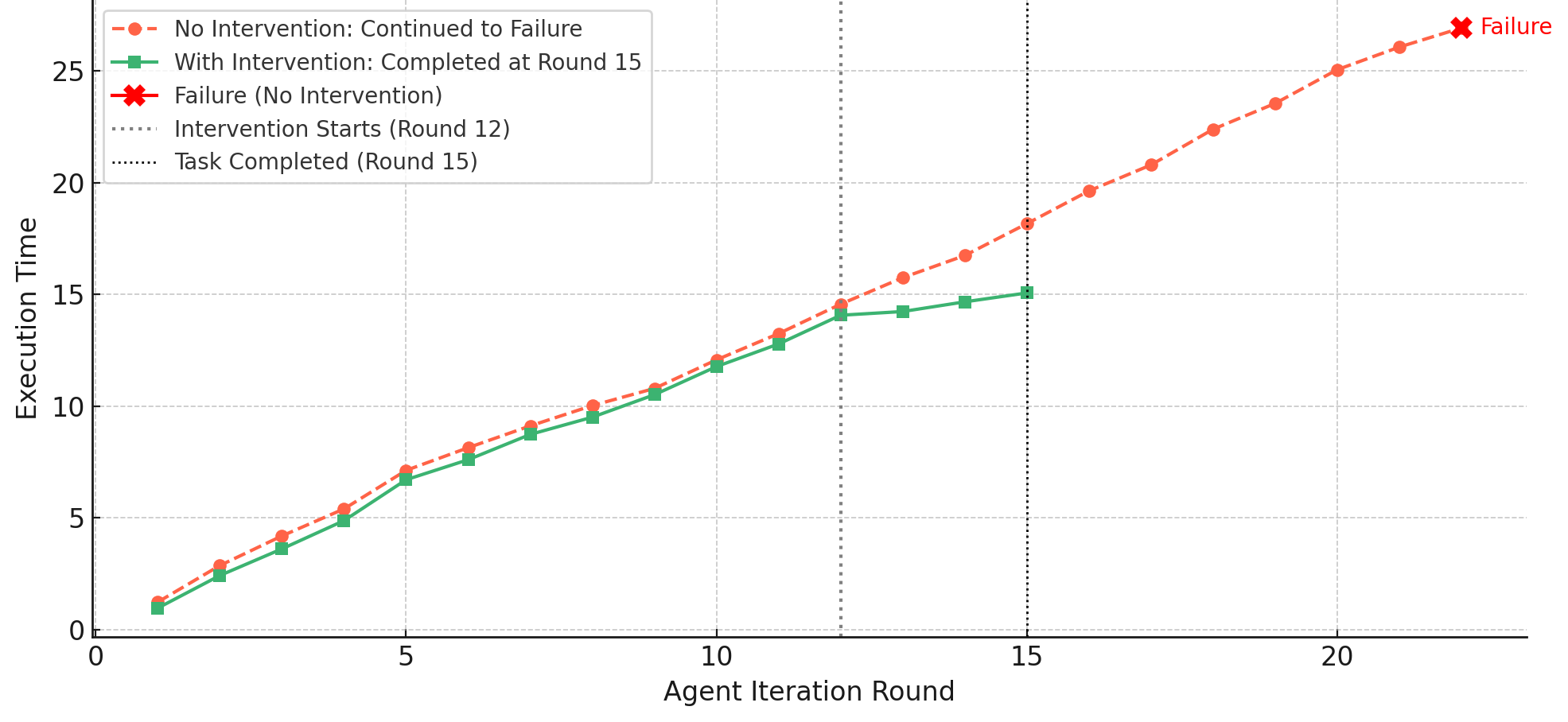
对比有无认知干预机制下,Agent 执行每轮任务所耗时间的变化趋势
未干预路径在执行至第 22 轮后依然未能完成任务,表现出明显的低效循环;当主动干预系统参与后,的 Agent 在第 12 轮收到系统提示后调整策略,并在第 15 轮顺利结束研究流程。
变化 4:动态深度调整
旧版本的一个硬伤是研究深度固定。简单问题可能浪费资源,复杂问题又研究不充分。新版本引入了动态深度调整机制。
Agent 会在研究过程中持续评估任务复杂度。当发现问题比预期复杂时,会主动请求扩展研究深度(最多可达 20 轮)。反之,如果早期就获得了充分信息,也会提前结束,避免无谓的资源消耗。
// 伪代码,仅供参考
if (isset($action_json['new_max_iterations'])) {
$suggested_max = $action_json['new_max_iterations'];
if ($suggested_max > $iteration && $suggested_max <= 20 && $suggested_max >= 5) {
$max_iterations = $suggested_max;
}
}这种灵活性带来的改变是显著的。举个例子:在开发阶段,我以“帮我对以下问题调用深入研究进行分析:智能汽车发展现状和未来趋势” 为问题测试 MolaGPT Deep Research 时,Agent 在第 1 轮时就意识到了问题的潜在复杂性,主动将深度由原本的 12 轮调整到 20 轮(最大值)。确保从政策、产业结构、技术发展、生态环境等尽可能多的角度进行分析。

但有趣的是,Agent 在第 6 轮时意识到了问题好像也没那么复杂。它在分析中写道:“考虑到研究已完成6轮,且已收集到较为全面的信息,继续深入可能不会带来显著的新发现。因此,我认为当前信息已足够充分来回答用户的问题,建议结束研究并提供最终总结。” 随后主动结束了研究过程。
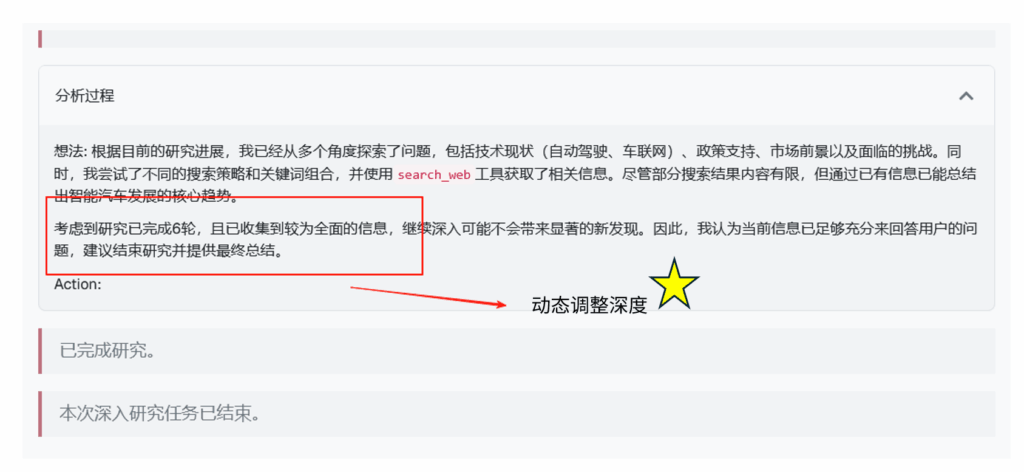
这种逻辑其实源于真正的研究者:他们不会在研究开始时就知道需要多少时间,他们会根据发现而不断调整他们的计划,动态深度调整让 MolaGPT Deep Research 也具备了这种自适应能力。
局限性
新版本虽然改进很多,但仍存在一些问题:
- 最主要的,幻觉问题依然存在:特别是在整合多个相互矛盾的信息源时,这些来源来源可能给出截然相反的预测。Agent 有时会试图“调和”这些矛盾,创造出一个看似合理但实际上并不存在的“中间观点”;
- 搜索 API 的语义理解能力有限:导致某些专业领域的搜索效果不理想;
- 串行执行效率问题:对于可以并行研究的任务,目前的架构无法充分利用;
- 长时间研究的资源消耗:20轮的深度研究可能需要较长时间和较多的API调用;
与旧版 MolaGPT Deep Research 的对比
我在旧版本的 Blog 文章中放上了一个问题示例:研究“深圳市各区 GDP的近年数据、增速变化、排位变化及原因分析”。
这个问题,新旧版本的表现差异明显。
旧版本会机械地搜索“深圳各区 GDP”、“深圳经济数据”等关键词,收集到信息后进行简单汇总。虽然能提供基础数据,但缺乏深度分析和洞察。而新版本的表现让我自己都有些惊喜。Agent首先制定了一个清晰的四步计划:搜集数据、提取权威来源、分析变化、归纳原因。
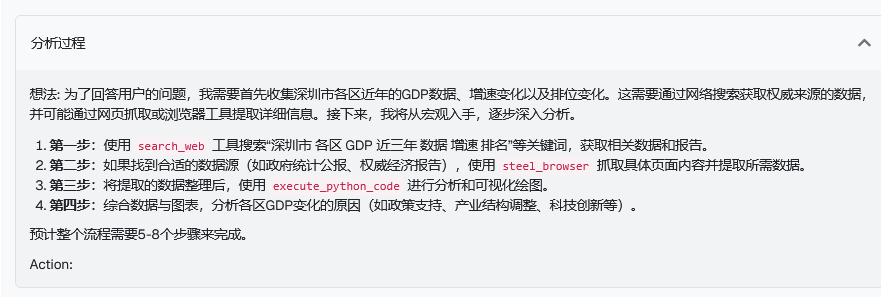
在后续的研究过程中,它先用 search_web 找到了 2023 年的初步数据,但很快意识到信息不完整。于是主动切换到 steel_browser,深入抓取了深圳统计局和各区政府的详细报告。发现缺少历史数据时,它没有放弃,而是调整搜索策略,从多个渠道补全了 2021-2022 年的数据,甚至在某个网页需要登录才可以查看时,选择使用截图分析来尝试绕过网页的登录限制。
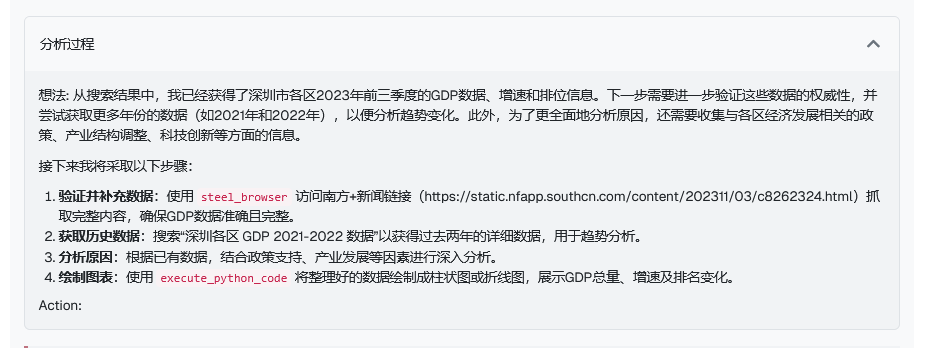
在数据处理上,Agent 不满足于罗列数字,而是调用 execute_python_code,在研究过程中自己编写代码计算了各区的同比增速,还生成了两张可视化图表,而在旧版本中,这一操作是由 Agent 研究结束之后的主模型代为生成的,Agent 并没有使用工具的能力。
在完成数据分析后,它意识到还需要解释“为什么”。于是开启了新一轮研究,从政策支持、产业结构、城市更新等多个角度寻找答案。最终的分析极具洞察力:“南山的增长源于科技创新集群、宝安受益于高端制造业升级和前海扩容、坪山凭借新能源产业异军突起、深汕合作区则是政策红利的典型案例……”
从制定计划到收集数据,从发现问题到调整策略,从数据分析到原因挖掘,新版 MolaGPT Deep Research 展现出的不是机械执行,而是真正的研究思维。这种“逢山开路,遇水架桥”的灵活性,正是 ReAct 框架赋予它的核心能力。

发表回复